TinyLLM
Models
| Model Name | Affiliation | Model Size | Release Date | 🔗 Link |
|---|---|---|---|---|
| Bloom | BigScience | 560M | 2022.11 | Bloom |
| Bloomz | BigScience | 560M | 2022.11 | Bloomz |
| Cerebras-GPT | Cerebras | 590M | 2023.03 | Cerebras-GPT |
| Cerebras-GPT | Cerebras | 256M | 2023.03 | Cerebras-GPT |
| Cerebras-GPT | Cerebras | 111M | 2023.03 | Cerebras-GPT |
| Danube3 | H2O | 500M | 2024.07 | Danube3 |
| Flan-T5 | Base | 2023.01 | Flan-T5 | |
| LaMini-GPT | MBZUAI | 774M | 2023.04 | LaMini-GPT |
| LaMini-GPT | MBZUAI | 124M | 2023.04 | LaMini-GPT |
| LiteLlama | ahxt | 460M | N/A | LiteLlama |
| OPT | Meta | 350M | 2022.05 | OPT |
| OPT | Meta | 125M | 2022.05 | OPT |
| Pythia | EleutherAI | 410M | 2023.03 | Pythia |
| Pythia | EleutherAI | 160M | 2023.03 | Pythia |
| PhoneLM | mllmTeam | 0.5B | 2024.11 | PhoneLM |
| Qwen1.5 | Alibaba | 0.5B | 2024.02 | Qwen1.5 |
| Qwen2.5 | Alibaba | 0.5B | 2024.09 | Qwen2.5 |
| SmolLM | Hugging Face | 360M | 2024.07 | SmolLM |
| SmolLM | Hugging Face | 135M | 2024.07 | SmolLM |
| TinyLlama | TinyLlama | 1.1B | 2023.12 | TinyLlama |
Evaluation Datasets
| Dataset Name | Explanation | 🔗 Link |
|---|---|---|
| ARC | Science question dataset for QA. - ARC-e : ARC-easy | ai2_arc |
| OBQA | a QA dataset modeled after open-book exams, designed to test multi-step reasoning, commonsense knowledge, and deep text comprehension. | openbookqa |
| BoolQ | QA dataset for yes/no questions | boolq |
| PIQA | QA dataset for physical commonsense reasoning and a corresponding | piqa |
| SIQA | question-answering, designed to evaluate social commonsense reasoning about people's actions and their social implications. | social_i_qa |
| WinoGrande | fill-in-the-blank problems | winogrande |
| HellaSwag | Common sense natural language reasoning | hellaswag |
Environment
Jetson Orin Nano 8GB RAM link python: 3.10.2
Evaluation Result
nan: Failed inference (memory issue)
1. Model Size (MB)
| Model | Parameters | ARC-e | BoolQ | OBQA | PIQA | SIQA | WinoGrande | Avg. |
|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT-111M | 111M | 423.624 | 423.624 | 423.624 | 423.624 | 423.624 | 423.624 | 423.624 |
| Cerebras-GPT-256M | 256M | 976.475 | 976.475 | 976.475 | 976.475 | 976.475 | 976.475 | 976.475 |
| Cerebras-GPT-590M | 590M | 2251.86 | 2251.86 | 2251.86 | 2251.86 | 2251.86 | 2251.86 | 2251.86 |
| LaMini-GPT-124M | 124M | 474.703 | 474.703 | 474.703 | 474.703 | 474.703 | 474.703 | 474.703 |
| LaMini-GPT-774M | 774M | 2952.7 | nan | 2952.7 | nan | nan | 2952.7 | 2952.7 |
| LiteLlama-460M-1T | 460M | 1761.19 | 1761.19 | 1761.19 | 1761.19 | 1761.19 | 1761.19 | 1761.19 |
| Qwen1.5-0.5B | 500M | 1769.97 | 1769.97 | 1769.97 | nan | 1769.97 | 1769.97 | 1769.97 |
| Qwen2.5-0.5B | 500M | 1884.59 | 1884.59 | 1884.59 | 1884.59 | 1884.59 | 1884.59 | 1884.59 |
| SmolLM-135M | 135M | 513.134 | 513.134 | 513.134 | 513.134 | 513.134 | 513.134 | 513.134 |
| SmolLM-360M | 360M | 1380.24 | 1380.24 | 1380.24 | 1380.24 | 1380.24 | 1380.24 | 1380.24 |
| bloom-560m | 560M | 2133.23 | 2133.23 | 2133.23 | nan | 2133.23 | 2133.23 | 2133.23 |
| bloomz-560m | 560M | 2133.23 | 2133.23 | 2133.23 | 2133.23 | 2133.23 | 2133.23 | 2133.23 |
| opt-125m | 125M | 477.75 | 477.75 | 477.75 | 477.75 | 477.75 | 477.75 | 477.75 |
| opt-350m | 350M | 1263.41 | 1263.41 | 1263.41 | 1263.41 | 1263.41 | 1263.41 | 1263.41 |
| pythia-160m | 160M | 619.213 | 619.213 | 619.213 | 619.213 | 619.213 | 619.213 | 619.213 |
| pythia-410m | 410M | 1546.23 | 1546.23 | 1546.23 | 1546.23 | 1546.23 | 1546.23 | 1546.23 |
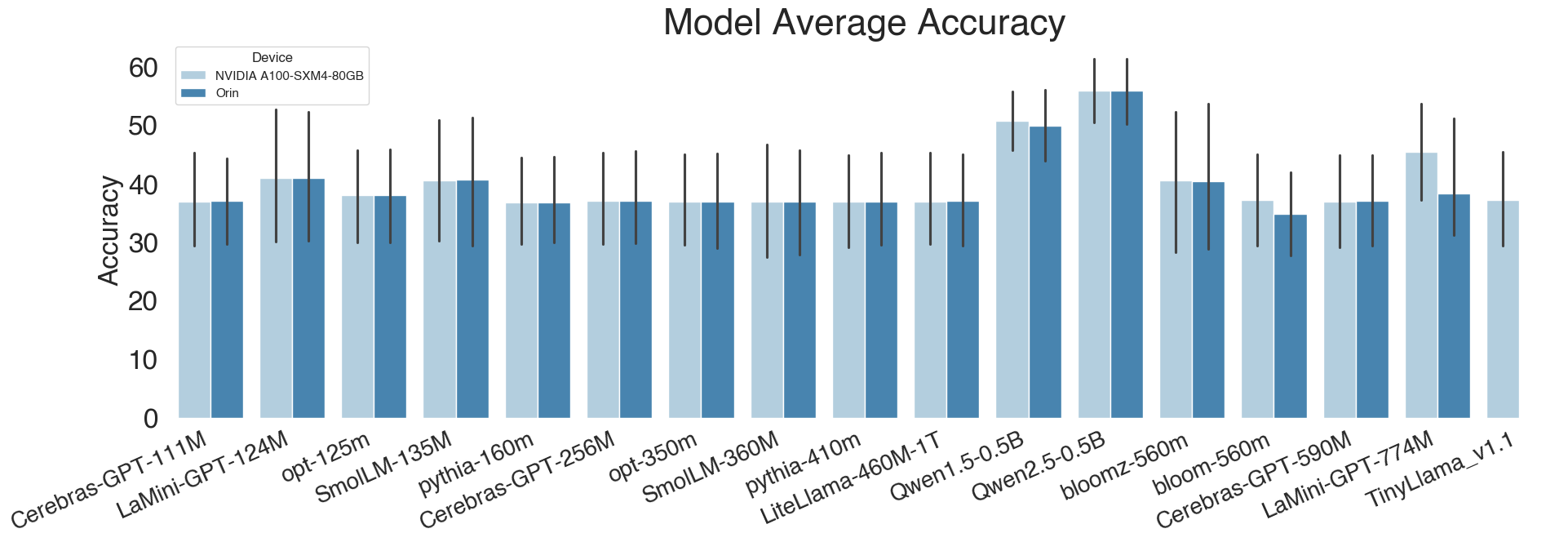
2. Accuracy (%)
| Model | Parameters | ARC-e | BoolQ | OBQA | PIQA | SIQA | WinoGrande | Avg. |
|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT-111M | 111M | 26.4912 | 38 | 25 | 49.2 | 33.7 | 49.5659 | 36.9929 |
| Cerebras-GPT-256M | 256M | 26.4912 | 38.1 | 25 | 49.2 | 33.7 | 49.5659 | 37.0095 |
| Cerebras-GPT-590M | 590M | 26.4912 | 37.9 | 25 | 49.2 | 33.7 | 49.5659 | 36.9762 |
| LaMini-GPT-124M | 124M | 24.9123 | 62.4 | 24 | 50.8 | 33.1 | 50.4341 | 40.9411 |
| LaMini-GPT-774M | 774M | 32.6316 | nan | 31.2 | nan | nan | 51.0655 | 38.299 |
| LiteLlama-460M-1T | 460M | 25.614 | 38.1 | 25.2 | 49.3 | 34 | 49.5659 | 36.9633 |
| Qwen1.5-0.5B | 500M | 54.7368 | 59.7 | 42 | nan | 42.3 | 50.8287 | 49.9131 |
| Qwen2.5-0.5B | 500M | 62.807 | 64.6 | 44.8 | 59.5 | 52.3 | 50.9077 | 55.8191 |
| SmolLM-135M | 135M | 24.2105 | 60.4 | 25.8 | 49.9 | 32.8 | 50.4341 | 40.5908 |
| SmolLM-360M | 360M | 21.7544 | 39.7 | 23.6 | 52.5 | 34.3 | 49.5659 | 36.9034 |
| bloom-560m | 560M | 26.3158 | 38.3 | 25.8 | nan | 33.7 | 49.5659 | 34.7363 |
| bloomz-560m | 560M | 24.2105 | 62.5 | 21.8 | 50.6 | 32.9 | 50.3552 | 40.3943 |
| opt-125m | 125M | 26.4912 | 43.4 | 25.4 | 49.4 | 33.7 | 49.487 | 37.9797 |
| opt-350m | 350M | 26.3158 | 38.4 | 24.8 | 49.9 | 32.6 | 49.5659 | 36.9303 |
| pythia-160m | 160M | 26.3158 | 38 | 25.2 | 48.6 | 33 | 49.2502 | 36.7277 |
| pythia-410m | 410M | 26.3158 | 37.8 | 25 | 49.2 | 33.7 | 49.6448 | 36.9434 |
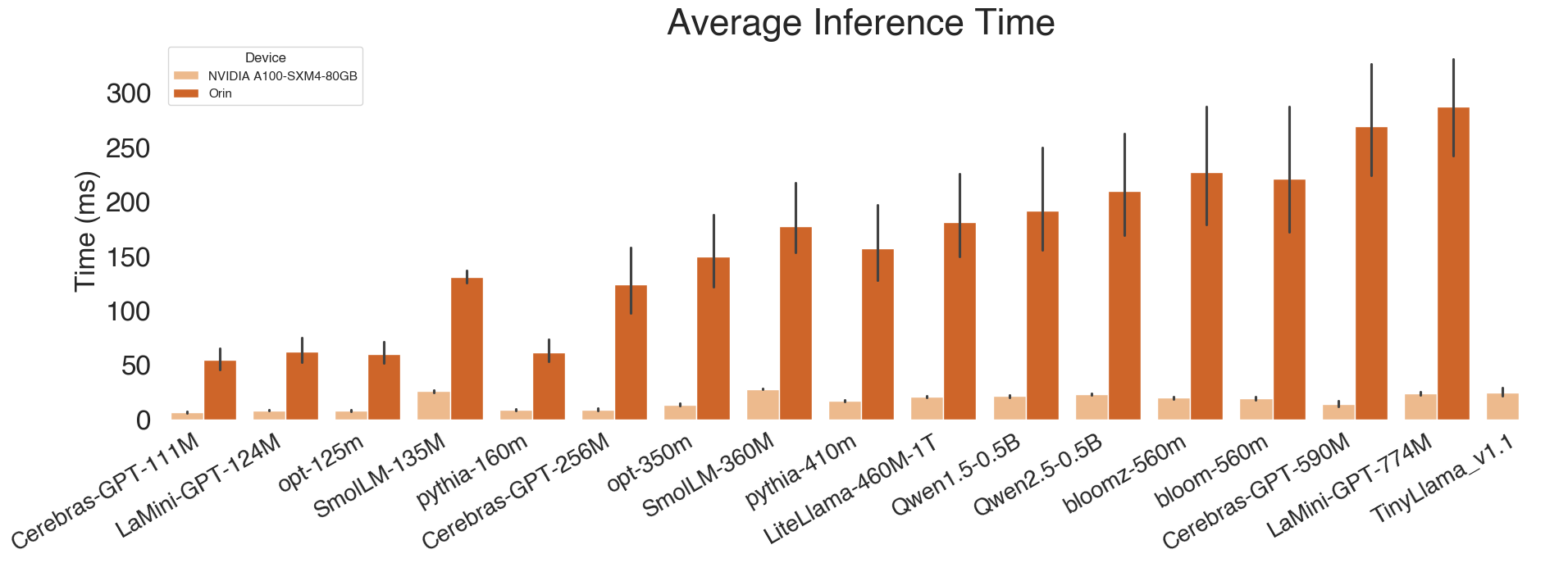
3. Inference Time (ms)
| Model | Parameters | ARC-e | BoolQ | OBQA | PIQA | SIQA | WinoGrande | Avg. |
|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT-111M | 111M | 47.8482 | 75.0534 | 42.6519 | 67.5944 | 46.5603 | 49.3566 | 54.8441 |
| Cerebras-GPT-256M | 256M | 118.458 | 197.908 | 104.827 | 118.09 | 125.461 | 76.8072 | 123.592 |
| Cerebras-GPT-590M | 590M | 251.496 | 407.803 | 227.772 | 279.49 | 252.317 | 195.598 | 269.079 |
| LaMini-GPT-124M | 124M | 55.5167 | 91.169 | 50.3607 | 70.0167 | 53.6331 | 51.48 | 62.0294 |
| LaMini-GPT-774M | 774M | 331.246 | nan | 288.771 | nan | nan | 241.842 | 287.286 |
| LiteLlama-460M-1T | 460M | 173.447 | 278.426 | 156.089 | 181.297 | 173.079 | 124.438 | 181.129 |
| Qwen1.5-0.5B | 500M | 175.618 | 305.815 | 155.574 | nan | 174.686 | 146.179 | 191.574 |
| Qwen2.5-0.5B | 500M | 197.737 | 330.037 | 173.806 | 213.579 | 197.794 | 143.201 | 209.359 |
| SmolLM-135M | 135M | 125.591 | 143.362 | 124.124 | 138.117 | 125.266 | 125.496 | 130.326 |
| SmolLM-360M | 360M | 161.715 | 274.149 | 151.589 | 176.19 | 158.66 | 143.47 | 177.629 |
| bloom-560m | 560M | 206.418 | 357.453 | 178.741 | nan | 213.107 | 149.083 | 220.96 |
| bloomz-560m | 560M | 206.628 | 357.817 | 178.633 | 257.519 | 213.568 | 148.324 | 227.081 |
| opt-125m | 125M | 56.6352 | 86.7192 | 51.8376 | 63.6035 | 55.3677 | 46.6623 | 60.1376 |
| opt-350m | 350M | 144.791 | 231.819 | 129.27 | 148.27 | 142.364 | 100.038 | 149.425 |
| pythia-160m | 160M | 57.3411 | 89.2453 | 53.2252 | 63.1686 | 55.5747 | 50.21 | 61.4608 |
| pythia-410m | 410M | 153.6 | 247.236 | 135.242 | 153.365 | 150.89 | 103.307 | 157.273 |
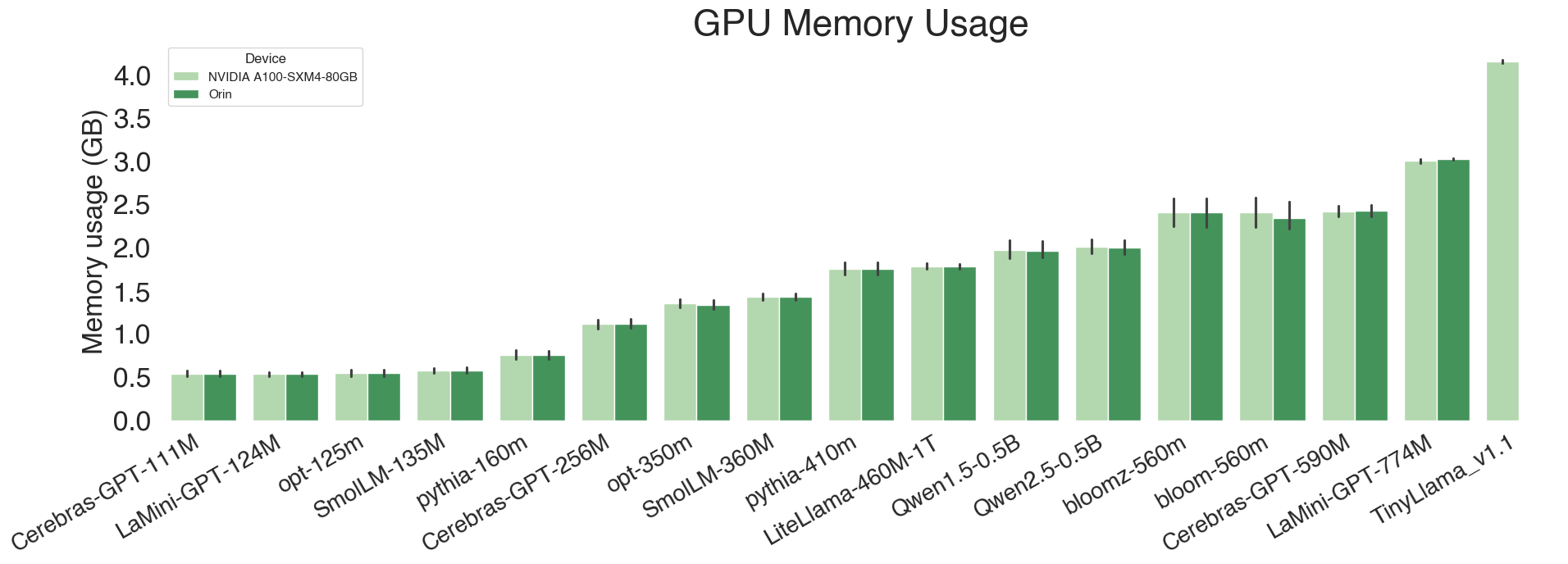
4. Peak GPU Memory Usage (GB)
| Model | Parameters | ARC-e | BoolQ | OBQA | PIQA | SIQA | WinoGrande | Avg. |
|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT-111M | 111M | 0.518592 | 0.607112 | 0.511304 | 0.604109 | 0.509212 | 0.48632 | 0.539441 |
| Cerebras-GPT-256M | 256M | 1.09269 | 1.21178 | 1.07552 | 1.20522 | 1.07341 | 1.04991 | 1.11809 |
| Cerebras-GPT-590M | 590M | 2.38433 | 2.55191 | 2.37 | 2.54645 | 2.36661 | 2.33764 | 2.42616 |
| LaMini-GPT-124M | 124M | 0.518301 | 0.582409 | 0.511014 | 0.580349 | 0.508922 | 0.499037 | 0.533339 |
| LaMini-GPT-774M | 774M | 3.03155 | nan | 3.02419 | nan | nan | 3.01209 | 3.02261 |
| LiteLlama-460M-1T | 460M | 1.76578 | 1.83748 | 1.75761 | 1.83512 | 1.75526 | 1.74412 | 1.78256 |
| Qwen1.5-0.5B | 500M | 1.93748 | 2.19273 | 1.90575 | nan | 1.89908 | 1.85993 | 1.959 |
| Qwen2.5-0.5B | 500M | 1.95148 | 2.15225 | 1.92665 | 2.14751 | 1.92128 | 1.89048 | 1.99828 |
| SmolLM-135M | 135M | 0.555858 | 0.633439 | 0.546275 | 0.631614 | 0.546517 | 0.534195 | 0.57465 |
| SmolLM-360M | 360M | 1.4055 | 1.49492 | 1.39445 | 1.49281 | 1.39473 | 1.38053 | 1.42716 |
| bloom-560m | 560M | 2.30397 | 2.71227 | 2.25459 | nan | 2.24332 | 2.17851 | 2.33853 |
| bloomz-560m | 560M | 2.30397 | 2.71227 | 2.25459 | 2.71267 | 2.24332 | 2.17851 | 2.40089 |
| opt-125m | 125M | 0.521742 | 0.614046 | 0.511907 | 0.611887 | 0.50906 | 0.495602 | 0.544041 |
| opt-350m | 350M | 1.30801 | 1.43236 | 1.29386 | 1.42981 | 1.28977 | 1.27041 | 1.33737 |
| pythia-160m | 160M | 0.727875 | 0.838728 | 0.719082 | 0.834872 | 0.717061 | 0.689547 | 0.754528 |
| pythia-410m | 410M | 1.7104 | 1.8971 | 1.68983 | 1.8946 | 1.6853 | 1.65406 | 1.75521 |
Thoughts
This was the very first project I worked on after joining a research lab as an intern — and honestly, it felt like a proper first project. On my first day, I was handed a Jetson Nano and told to set it up. My first thought was: what is this? It's so slow and frustrating! That was basically my first real encounter with Ubuntu. It felt like dealing with an old computer, but surprisingly it supported CUDA (though not the latest versions).
At the time, I had no idea what I was even doing. Dataset? HuggingFace? What are those? I only started to get it after seeing others measuring accuracy — oh, so this is on-device AI! It's running entirely on this GPU without any server. That’s when it clicked. When I saw models getting only 30% accuracy, I was like, is this even working? Feels like random guessing. Turns out it was because no fine-tuning had been done yet.
It was also fascinating to learn that there are so many tiny LLMs out there, and the goal was to compare them in terms of latency and accuracy to see which ones perform best.
I also got introduced to WandB and started learning how to write automation scripts. It was actually my first time automating anything. Since the measurements were slow and involved lots of repetition, I finally understood why automation matters. Ever since then, I’ve preferred automating workflows in all my projects.
Looking back, I had no idea what I was doing and just followed along at first — but I think my professor intentionally gave me this as a starting point: explore whether LLMs could run on small edge devices and what kind of efficiency they could reach. But along the way, I ended up learning so many valuable things — Docker, WandB, automation, conda environments, data visualization, and more.
It might not seem like a big deal later, but for someone who started out knowing nothing, this was a really important project. It gave me a solid foundation and made me feel like I was finally part of a research group.