| ArXiv | https://arxiv.org/abs/2508.07871 |
|---|---|
| Author | Yanshu Li, Jianjiang Yang, Zhennan Shen, Ligong Han, Haoyan Xu, Ruixiang Tang |
| Affiliation | 1Brown University 2University of Bristol 3MIT-IBM Watson AI Lab 4University of Southern California 5Rutgers University |
Key Differentiator
- query-cross attention이 decoder layer 진행 중, 특히 shallow layers (6~10) 이후에 증가하는 현상을 관찰
- query 마지막 토큰이 image token에 주는 attention의 layer 간 증가량을 relevance 신호로 사용하여, query-guided reasoning 과정에서 새롭게 중요해진 토큰을 선택하는 방식
- query 기반 attention과 representation similarity를 결합해 이미지 컨텍스트 토큰의 중요도를 재평가하고, In-Context Learning에 더 적합한 시퀀스를 재구성
Why I chose this paper?
- Motivation for token-level optimization
- GOLD가 단순한 Coarse-to-fine 알고리즘 기반이라 token-level optimization을 원했음.
- Interest in sequential GUI settings
- GOLD single-task setting 타겟이라서 sequential GUI tasks로 확장하기를 원했음.
- I want ideas for efficient computation under multi-image inputs.
Abstract
Large Vision-Language Models (LVLM)에서 이미지 토큰이 sparse하기 때문에 reasoning에 기여하지 않는 토큰이 다수를 차지함. → cost 상당
그래서 image token pruning을 사용함.
- 하지만, single-image task에 초점이 맞춰짐
- multimodal in-context learning 상황을 고려하지 않음.
- 기존 프루닝 기법을 그대로 적용하면 정확도 drop 발생
이 논문 CATP에서는 멀티모달 ICL 환경에 특화되어
- 이미지–텍스트–이미지 간의 맥락적 관계(context)를 반영하도록 설계
- 2-stage progressive pruning 구조를 사용
→ 결과적으로 이미지 토큰의 77.8% 제거하면서 평균 선은 0.6% 향상, 추론 지연시간 10.78% 감소를 보임
Related Work
Large Vision-language Models (LVLMs)
- LLM이 발전하면서 이미지, 텍스트 동시에 처리하는 LVLM 확장됨
- vision encoder, projector, and LLM decoder 구조
- 비효율
- 텍스트 토큰에 비해 정보 밀도가 현저히 낮음
- 심각한 이미지 토큰 중복 발생
In-context Learning (ICL)
- 파라미터 업데이트 없이 예시 몇 개(ICDs)만으로 즉각적인 태스크 적응
- Multi-model로 확장되어 이미지 + 텍스트 포함하는 ICL이 중요해짐
- 근데, 이미지 토큰들은 텍스트 3토큰에 비해 sparse함. (중요한 부분의 밀도가 낮음)
- 각 예시마다 이미지 있고, 쿼리에도 이미지 포함되어서 입력 길이 길어짐
- ICL 장점이 가볍고 빠르다는 것인데, 이미지 토큰 중복때문에 오히려 장점이 약화된다!
LLaVA-Next 연산량 증가 예시
이미지 1장 → 576 tokens
VizWiz 데이터셋에서 2-shot ICL
- single-image inference 대비 3.2× 연산량
- text-only inference 대비 14.3× 연산량
Image Token Pruning
이미지 토큰 중복 문제 해결하려고 training-free image token pruning 연구들이 나옴

3-shot in-context sequence
앞에 3개의 ICD를 하나의 시퀀스로 넣고 마지막에 Query주는거
Attention-based Image Token Pruning (b)
- LLM decoder 내부에서 이미지 토큰이 받는 attention weight를 중요도의 지표로
- 이미지와 텍스트가 실제로 상호작용하는 지점을 활용
- 단점 : Attention shift 문제
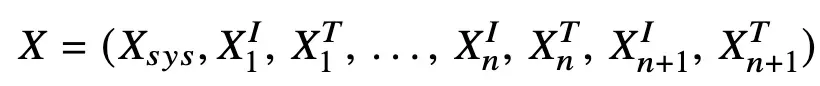
여기서 X1I(이미지)와 X1T(텍스트) 토큰이 interleaved(끼워넣기) 형식임
이미지 토큰을 펼치면 하단 토큰이 해당 텍스트 토큰과 가까워짐.
Transformer attention은 가까운 위치 토큰에 편향됨 (positional bias)
Diversity-based Image Token Pruning (c)
- Vision encoder + projector 이후에, 텍스트와 상호작용하는 Decoder에 입력되기 전 단계에서 이미지 토큰들 간의 feature similarity를 기준으로 중복 토큰을 제거
- 각 이미지를 독립적으로 처리 → Figure(c)에서 이미지마다 64개 토큰을 균등하게 남김
- DivPrune https://arxiv.org/abs/2503.02175
- 단점: 멀티모달 ICL에서 필요한 cross-image, image–text, context-level interaction을 포착X
→ 멀티모달 ICL에서는 fine-grained pruning 실패가 발생
CATP (d)
모든 ICD를 하나의 context로 봄
이미지마다 토큰수가 다름 (기여도 기반임)
sequence 내의 복잡한 cross-modal interactions
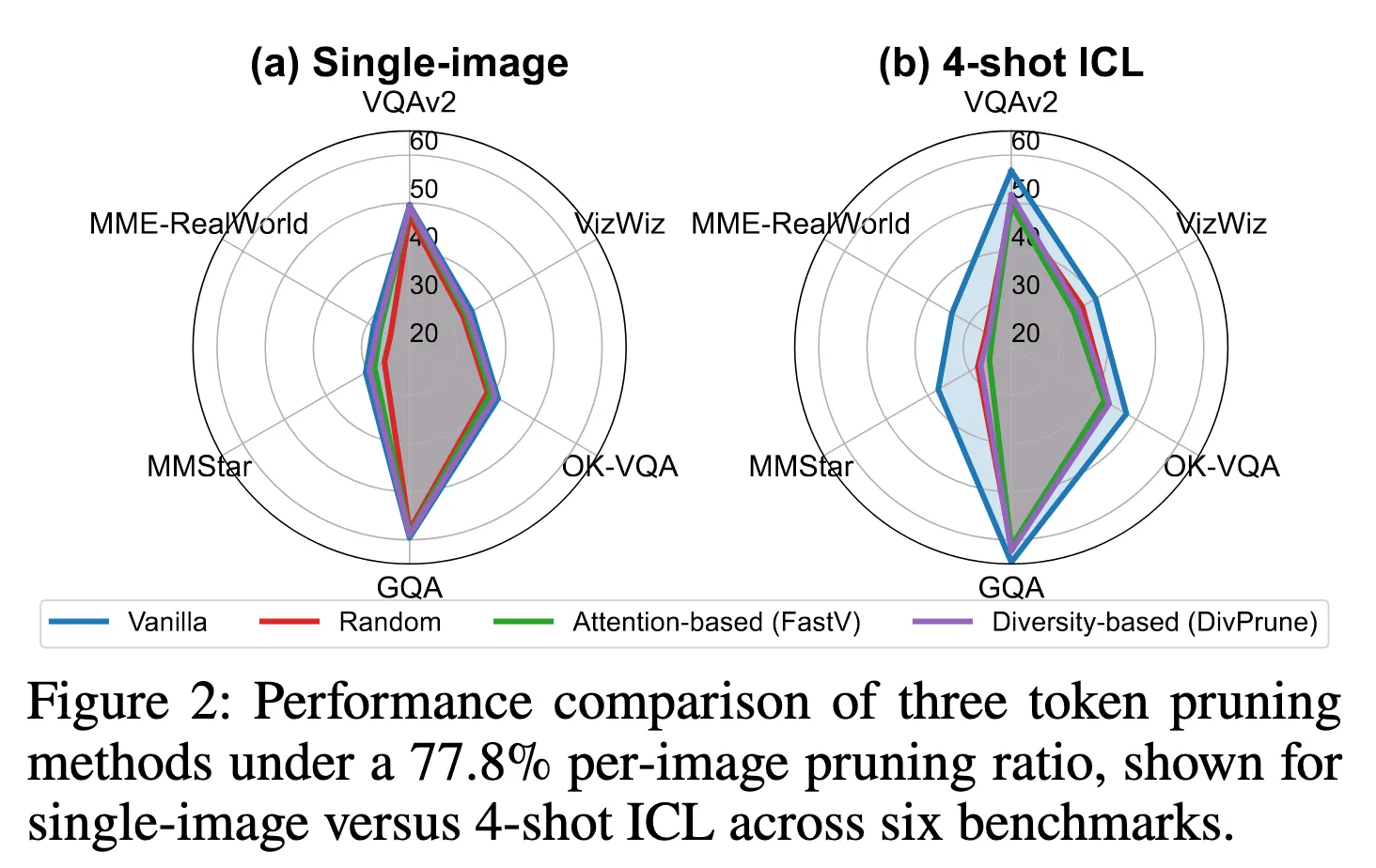
Single-image setting에서는 괜찮은데, 4-shot으로 가면 Random보다도 낮거나 비슷한 성능을 보임
→ 기존 프루닝 기법이 멀티모달 ICL에는 맞지 않는다.
Related Work 결론
: 멀티모달 ICL에서는 “개별 이미지 내 중요 토큰”이 아니라 “시퀀스 전체 맥락에서 기여하는 토큰”을 식별하는 새로운 기준이 필요하다!!
Method
Preliminary and Motivation
Multimodal In-Context Sequence
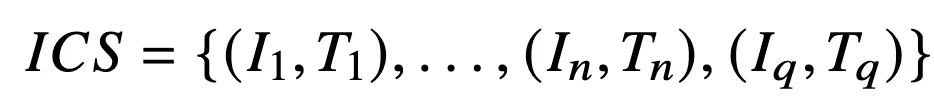
- query도 ICD(in-context demonstration)처럼 image + text 쌍이다.
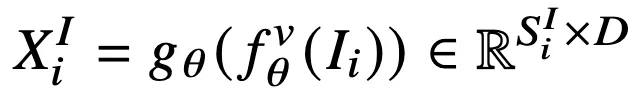
- 이미지가 토큰으로 변환되는 과정
- f : Vision encoder, g : projector
- S : 토큰수 (모델마다, 입력 해상도마다 달라짐)
→ 이미지 토큰 중복이 발생
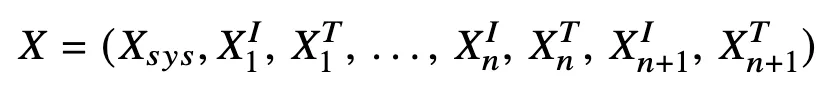
최종적으로 전체 토큰 시퀀스는 이런식으로 image랑 text가 interleaved (끼워넣는) 형태로 배치됨
모든 image token은 같은 이미지 토큰끼리만 상호작용하는 것이 아니라,
다른 이미지, 다른 텍스트, query와 동시에 상호작용!!
기존 Diversity-based pruning은 이 타이밍에 일어남.
Decoder 이전 (image token feature들만 존재, text, query 정보 없음 → image 내부 정보만으로)
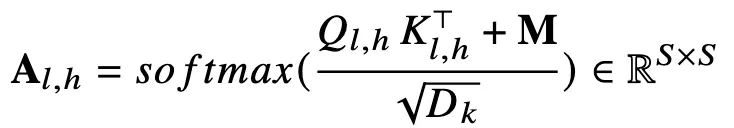
위의 시퀀스가 이 N-layer Transformer decoder에 입력되어
→ 즉 모든 image token은 모든 text token과 연결됨
기존 Attention-based pruning은 이 타이밍에 일어남.
decoder 내부 특정 layer에 적용
→ attention은 layer마다 의미가 달라지고, interleaved 구조에서는 attention shift 발생
→ attention값이 실제 기여도가 아니다.
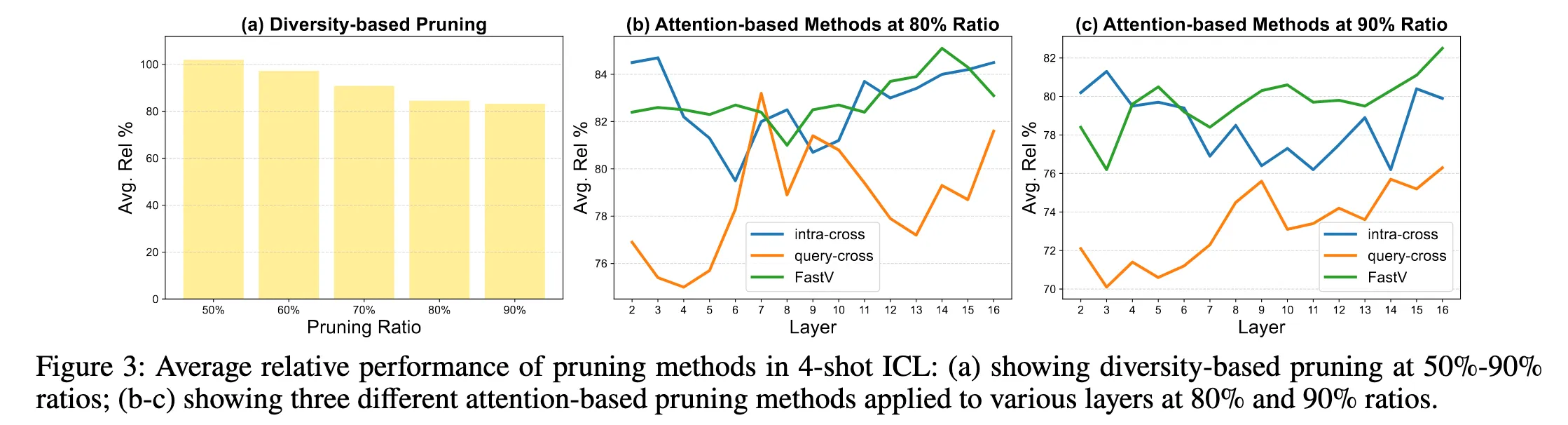
Figure3 (a)
diversity-based pruning
각 이미지 내부에서만 토큰 중요도를 판단 → 다른 이미지, 텍스트, query 정보를 전혀 보지 못함
Figure3 (b), (c)
어떤 attention을, 어느 레이어에서 쓰느냐에 따라 결과가 완전히 달라진다
- FastV (기존 방식)
- image token이 모든 토큰으로부터 받은 attention 총합
- Intra-cross
- image token이 자기 image–text pair 내부의 텍스트 토큰들로부터 받은 attention
- “image–text alignment가 중요한 초기 레이어에서는 이게 더 맞지 않을까?”
- Query-cross
- image token이 query sample의 토큰들로부터 받은 attention
- “ICL에서는 결국 query가 중요하니, query가 주목하는 토큰이 중요하지 않을까?”
→ Static single-layer attention은 멀티모달 ICL에서 토큰 중요도를 안정적으로 반영하지 못함
- attention shift가 누적되어 높은 attention ≠ 중요한 token
→ 멀티모달 ICL에서 복잡하게 얽힌 image–text–query 상호작용에서
전체 시퀀스의 reasoning에 실질적으로 기여하는 image token을 어떻게 식별할 수 있는가?
Contextually Adaptive Token Pruning
Overview
- 멀티모달 ICL에서는 여러 이미지와 텍스트가 하나의 reasoning context를 형성
→ image token의 중요성은 이미지 내부, 단일 attention 값이 아닌 시퀀스 전체 맥락(context)이 중요
- Stage 1: Context-aware Coarse Pruning
- Stage 2: Query-guided Fine-grained Pruning
- Stage 1만 사용하면
- coarse pruning까지만 가능
- fine-grained 실패
- Stage 2만 사용하면
- decoder 부담 과다
- attention noise 심각
“decoder 이전의 context-aware filtering + decoder 내부의 query-guided refinement”
Stage 1: Context-aware Coarse Pruning
- Vision encoder + projector 이후, LLM decoder 입력 직전 (diversity-based pruning처럼)
- 목적: 멀티모달 ICL 시퀀스에서 맥락(context)과 거의 상호작용하지 않는 image token을 decoder에 들어가기 전에 제거
- 기존 diversity-based pruning
- image token 간 feature similarity만 사용
- 이미지 내부 중복 제거에만 집중
- 고려하지 않는 정보 : 해당 이미지의 텍스트, 다른 ICD 이미지, query 이미지, 전체 ICL 시퀀스
- 멀티모달에서 중요하지만 맥락 의존적인 토큰을 무차별적으로 제거하는 문제
Diversity 항 Fdiv(Yi)
기존 diversity-based pruning 사용
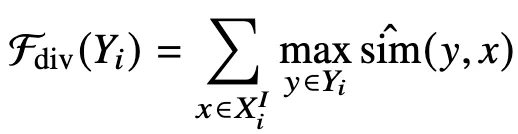
- 선택된 image token 집합 Yi 가 원래 image token 공간 XiI 를 얼마나 잘 대표(coverage)하는지 측정
- submodular : 이미 선택된 토큰 수가 많을수록 token을 하나 더 추가할 때의 이득이 감소
Alignment 함수 Falign(Yi)
image–text alignment score
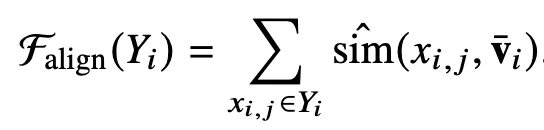
- 각 image token이 text summary
vˉi와 얼마나 의미적으로 가까운지 측정vˉi: 해당 image에 붙은 텍스트 토큰들의 hidden state를 average pooling
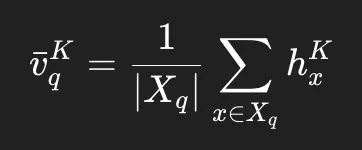
- modular : 각 원소의 점수가 서로에게 전혀 영향 안 주는 함수
최종 목적함수
: 둘의 합을 최대화하는 이미지 토큰 집합
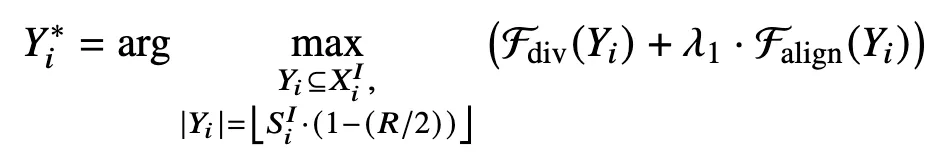
- Greedy selection
- submodular인 Fdiv + modular인 Falign 이라서 더한 최종도 submodular → Greedy가능
- 매 단계마다 “지금 추가했을 때 Fdiv + Falign이 제일 많이 오르는 토큰”을 하나씩 추가해도 결과 좋음
Stage 2: Query-guided Fine-grained Pruning
- LLM decoder 내부의 두 개의 얕은 decoder layer만
- Layer K → ICD 이미지 토큰 pruning (context pruning)
- Layer K+1 → Query 이미지 토큰 pruning (query pruning)
Attention growth
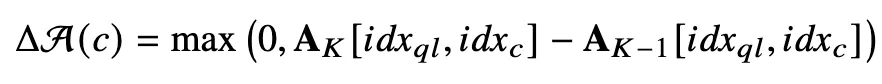
- Ak = k번째 layer의 attention matrix
- layer K−1 → K 로 넘어가면서 query가 해당 token을 더 사용하게 되었는지 측정
Context token 중요도 점수
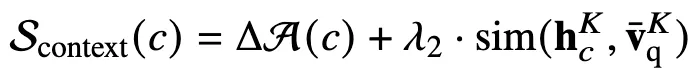
- ΔA(c): query가 새롭게 주목하기 시작한 token인가?
- sim(hcK,vqK): token 의미가 query 의미와 맞는가?
- pruning ratio R 달성까지 Scontext 낮은 순으로 제거
Query token 중요도 점수
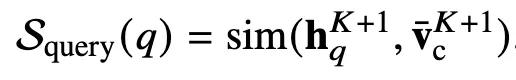
- Query token 의미가 위에서 남겨진 ICD(context) 토큰 의미와 맞는가?
- pruning ratio R 달성까지 Scontext 낮은 순으로 제거
왜 Stage2에서 Query를 보는가?
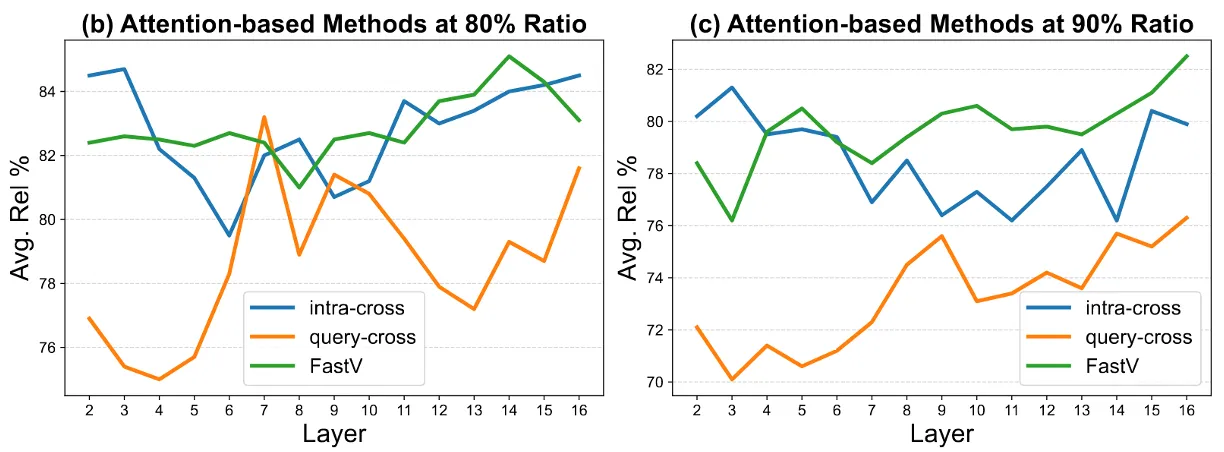
- 레이어 진행 중 query-cross 이 급격히 증가하는걸 볼 수 있음
→ 이는 디코더의 Layer 도중에 query와의 상호작용이 커진다는 것
Overview
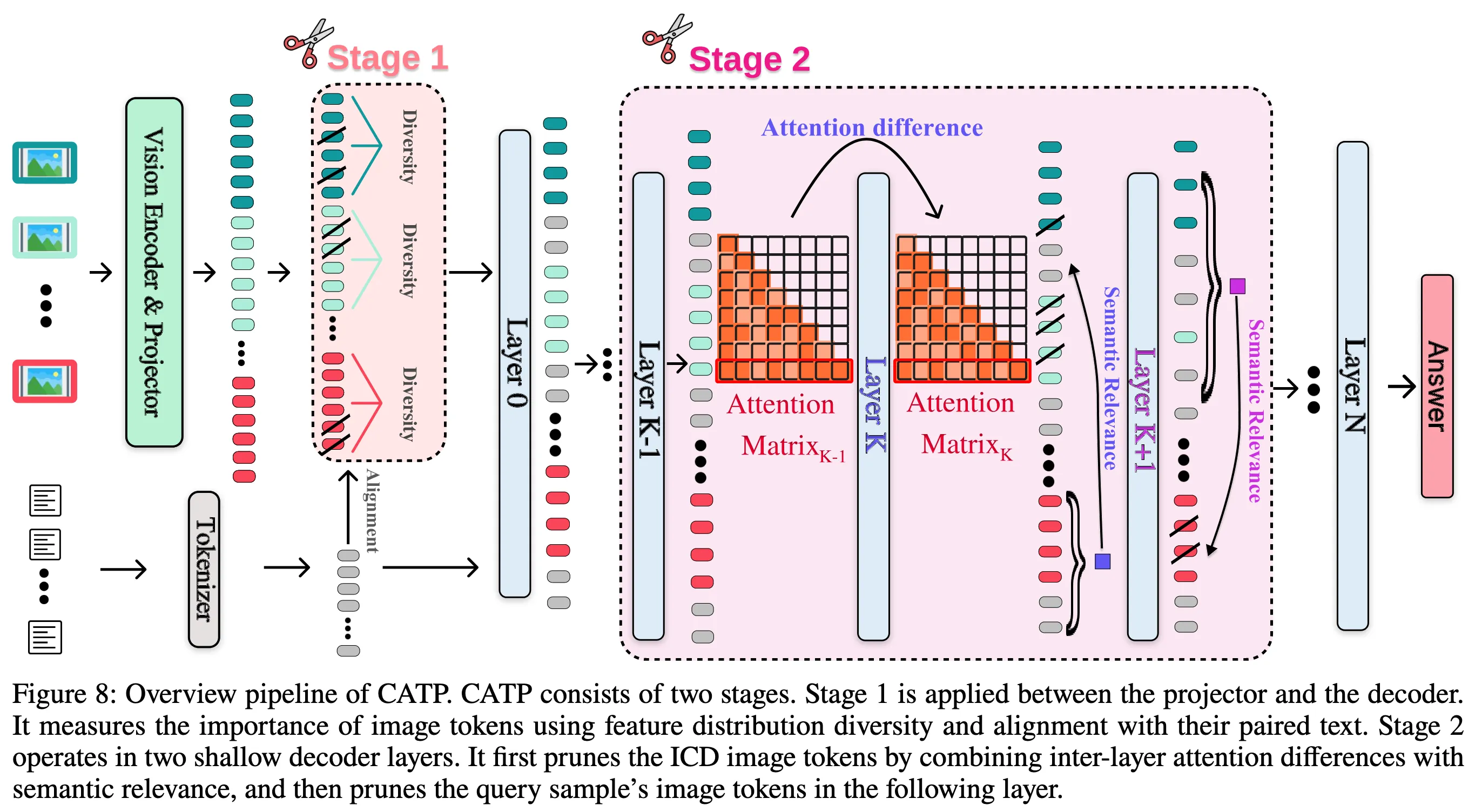
Stage1: 처음엔 대충 중요한 그림 조각만 남기기
- Falign: text summary와 alignment해서 텍스트 토큰과 얼마나 연관있는지
- Fdiv: 다른 토큰들과 얼마나 잘 대표(coverage)하는지
- 둘의 합을 최대화하는 토큰 집합을 남김
Decoder 진입 (Layer 0 → K-1)
- 모델이 query 중심으로 사고를 시작함
Stage2: 질문(Query)을 기준으로 정말 쓸모 있는 조각만 정밀하게 남기기
- Attention difference (Layer K-1 → K)
지금 attention 큰 애가 중요하겠지→ FastV 방식인데, 이렇게 안함!!!!
- 이 질문을 처리하면서 갑자기 중요해진 토큰이 뭐지?
- Layer K: ICD(context) 토큰 정리
- 기존 pruning은 각 이미지마다 같은 비율로 자르지만, 이건 ICD간에도 자르는 토큰 수가 다름
- ICD 간 차별 pruning →멀티모달 ICL 진짜 중요한 포인트
- Layer K+1: Query 이미지 토큰 정리
- 반대로 남아 있는 ICD(context) 토큰을 기준으로 query 이미지에서 맥락안맞는 것들도 pruning
- 이후 Layer
- 앞에서 토큰 많이 줄인 상태로 계산
Experiments
Setup
- LLaVA-Next-7B 주로 사용, LLaVA-1.5. Qwen2.5-VL 추가 사용
- pruning은 inference-time 에만 적용
- 멀티모달 question answering 중심 benchmark
- VQAv2, GQA, VizWiz, TextVQA, OK-VQA, MMBench
Main Results
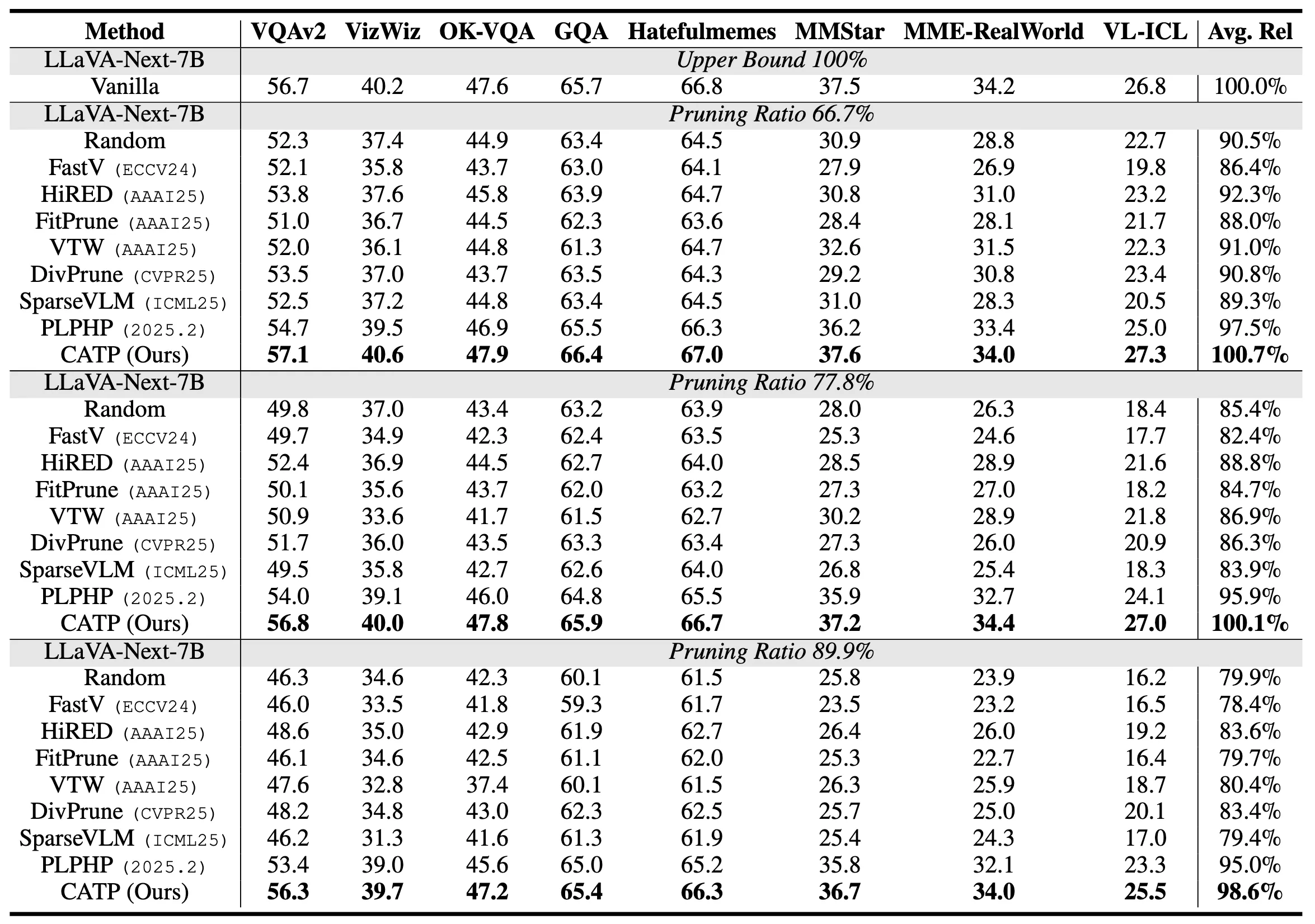
각 Baseline 설명
- FastV → decoder attention 크기를 기준으로 image token을 제거하는 attention-based pruning
- DivPrune → image token embedding의 다양성(coverage)을 기준으로 제거하는 diversity-based pruning
- FitPrune → image token과 텍스트 간 feature 유사도를 기준으로 제거하는 feature-alignment 기반 pruning
- VTW → image token 중요도를 학습된 가중치로 조절하는 token weighting 기반 soft pruning
- HiRED → 계층적 relevance 판단으로 token을 선택하는 hierarchical routing 기반 pruning
- SparseVLM → 모델 구조 자체에 sparsity를 도입하는 architecture-level sparse VLM
- PLPHP → 학습된 정책(policy)으로 token을 제거하는 policy-learning 기반 pruning
- 애초에 VLM / LVLM을 전제로 설계된 pruning → 다른 애들보다 멀티모달 환경에 조금 더 친화적
- 하지만, query가 policy 입력 중 하나일 뿐 pruning 기준점이 아님.
- CATP → 멀티모달 ICL에서 query를 기준으로 context 전체를 적응적으로 줄이는 context-aware, query-guided pruning
기존 방법들은 Random하게 pruning하는 결과와 비슷하거나 오히려 더 낮은 결과를 보이기도 함.
66.7%와 77.8% 모두 바닐라 모델에 비해 성능이 향상, 89.9%에서 살짝 떨어짐.
Efficiency Analysis
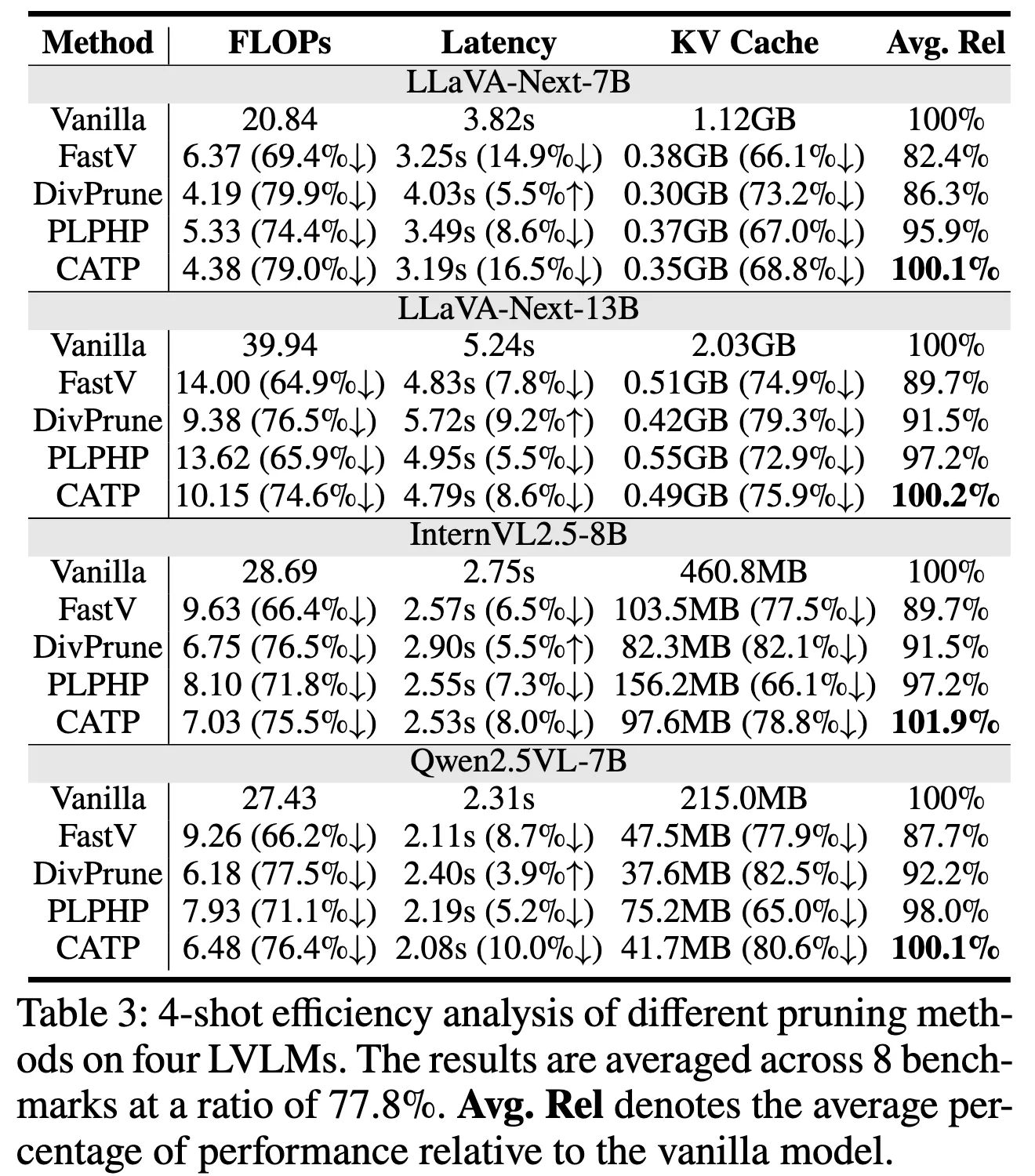
GPT의 해석Wen et al. (2025a)에 따르면 FLOPs와 KV Cache는
token pruning의 실제 실행 비용을 반영하지 못하며,
pruning 연산·메모리 접근·병렬화 효율까지 포함하는 latency만이
token pruning 효율의 가장 신뢰 가능한 지표이고,
이 기준에서 CATP는 기존 방법들과 질적으로 다른 효율성을 보인다
- pruning을 정해진 layer(K, K+1) 에서만 수행
- 토큰을 실제로 완전히 제거
→ 이후 layer들은 더 짧은 시퀀스를 그대로 dense하게 처리
→ GPU 친화적인 연산으로 FLOPs
- 토큰을 early하게 제거
→ 이후 layer에서 KV cache 크기 자체가 작아짐
Impact of each stage

decoder 이전에서 불필요한 image token을 먼저 제거해야
Stage 2의 attention 및 relevance 기반 판단이 왜곡 없이 작동할 수 있음
Stage 1도 꼭 필요하다는걸 보여줌
Impact of hyperparameters
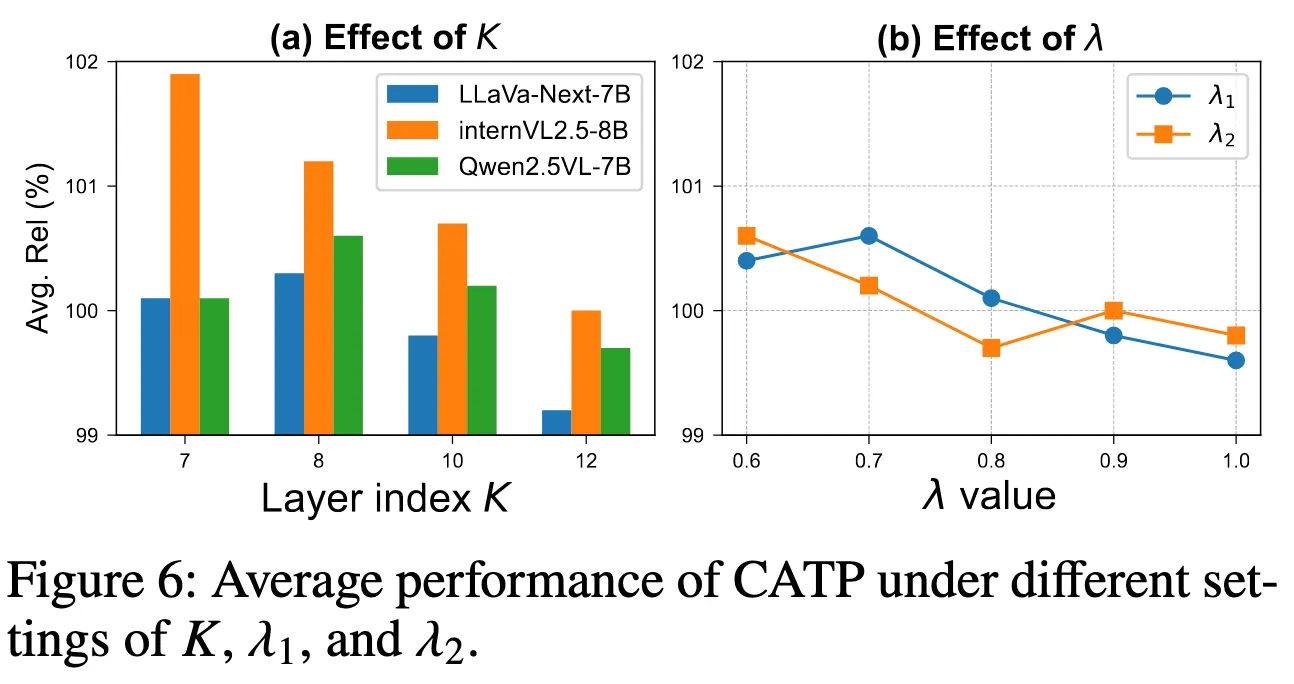
- K: Progressive adaptation 시작 layer (=6, 무거운 모델에서는 10)
- query–context 상호작용이 언제 본격화되는지
- Stage 1의 λ₁ (=0.7)
- λ₁이 너무 작은 경우 pruning 기준이 거의 alignment 위주로 작동
특정 텍스트와 강하게 대응되는 token만 남음 image 내부의 공간적·시각적 다양성 손실
- λ₁이 너무 작은 경우 pruning 기준이 거의 alignment 위주로 작동
Conclusion
- training-free로 멀티모달 ICL에 특화된 이미지 토큰 프루닝
- 2 Stage 구조로 입력된 in-context sequence 전체를 기준으로 ICL 과정에 중요한 이미지 토큰만 선택
- performance, efficiency 둘 다 향상
- 멀티모달 ICL 연구 자체가 공백이었는데 효율적으로 개선함
→ LVLM 발전에 insight 제공했다!
Limitation
- attention difference가 의미적 중요도(semantic necessity)를 보장한다는 증명이 없음
- 중요한 정보가 그냥 처음부터 attention이 높다면?
- attention 변화가 positional bias layer normalization 같은 이유로 일어났다면?
- decoder-centric LVLM을 전제로 하고, encoder–decoder 분리형, early fusion 구조, cross-attention 중심 구조에 안맞는다.
Future Work
Importance Persistence / Temporal Contribution Modeling
- Layer 하나에서 attention difference 하나를 신호로 쓰지 말고, 다음같은 토큰에 가중치 주거나 보호
- 처음부터 끝까지 계속 참조되는 토큰
- 여러 query step에서 반복적으로 선택되는 토큰
- multi-step reasoning, long-horizon ICL, agent-style inference 확장
GUI Grounding 확장
- layer 간 difference가 아니라 action 전후로 attention difference로 확장해보자!
- 이미 있는 GUI Grounding 논문은 둘 다 Vision 기반이 아니고, Action(click, type, scroll) 이후 HTML/DOM tree의 변경 사항을 중심으로 다음 행동 후보를 구성
- state diff가 큰것만 남기는 논문은 이미 많음 (로봇 / embodied VLA)
- 추가로 reasoning diff 하면 질문(query)에 의해 새롭게 중요해진 것을 추가적으로 걸러내는 역할
- 생각해본 아이디어
- 같은 디코더 layer K에서 (query의 영향력이 커지는 layer K를 이 논문처럼 찾아서)
- action 전 입력(state_t)을 넣었을 때의 attention
- action 후 입력(state_t+1)을 넣었을 때의 attention 차이 가 큰 걸 남기고,
- 나머지 K+1 번째 Layer부터 pruning된 채로 진행
- GUI가 특히 다른 sequential보다 state 변화량이 매우 커지는 경우가 많아서 state diff 외에도 이걸 추가해야 많은 token pruning이 가능할듯?
Q&A
논문 Presentation 발표 중 제대로 답변 못한 Q&A
Multimodal ICL에서 token duplication(=redundancy) 문제 이유
As shown in Figure 1(a), every ICD and the subsequent query sample include an image, so the image token redundancy that is already a bottleneck in single-image tasks becomes even more acute.
duplication 문제는 원래 single image에서도 이미 존재함
: image token들이 feature space에서 거의 동일한 embedding을 형성해서 인접한 부분 (특히 배경) 등에서 비슷한 cluster → near-duplicate image token
특히 여러 이미지가 interleaved 되는 ICL 구조에서는
동일한 encoder와 projector를 거친 비슷한 구조의 여러 이미지가 하나의 prompt에 반복 삽입되므로, 중복 구조가 이미지 간에도 누적되어 심해진다.
pruning 이후 position embedding은 어떻게되는가?
masking이 아닌 진짜 제거하는 pruning이면 transformer에서 position embedding을 어떻게 처리하는가?
논문에서는 pruning 이후 position embedding 처리에 대해 명시적으로 설명이 없음.
기존 논문들도 position embedding을 다시 부여하거나 유지하는 특별한 보정은 딱히 안한다.
남은 token을 연속 시퀀스로 재배열하고 position embedding을 다시 부여
→ 기존 pruning 연구들은 절대 위치 보존보다는, pruning 이후에도 reasoning에 필요한 상대적 관계가 유지되는지를 더 중요하게 가정
⭐️⭐️⭐️ 왜 query랑 비교를 stage 2에서 해야하는가?
query-cross shows a sharp rise in the shallow layers, roughly layers 7 to 10, indicating that after perception, the LVLM shifts to query-guided reasoning
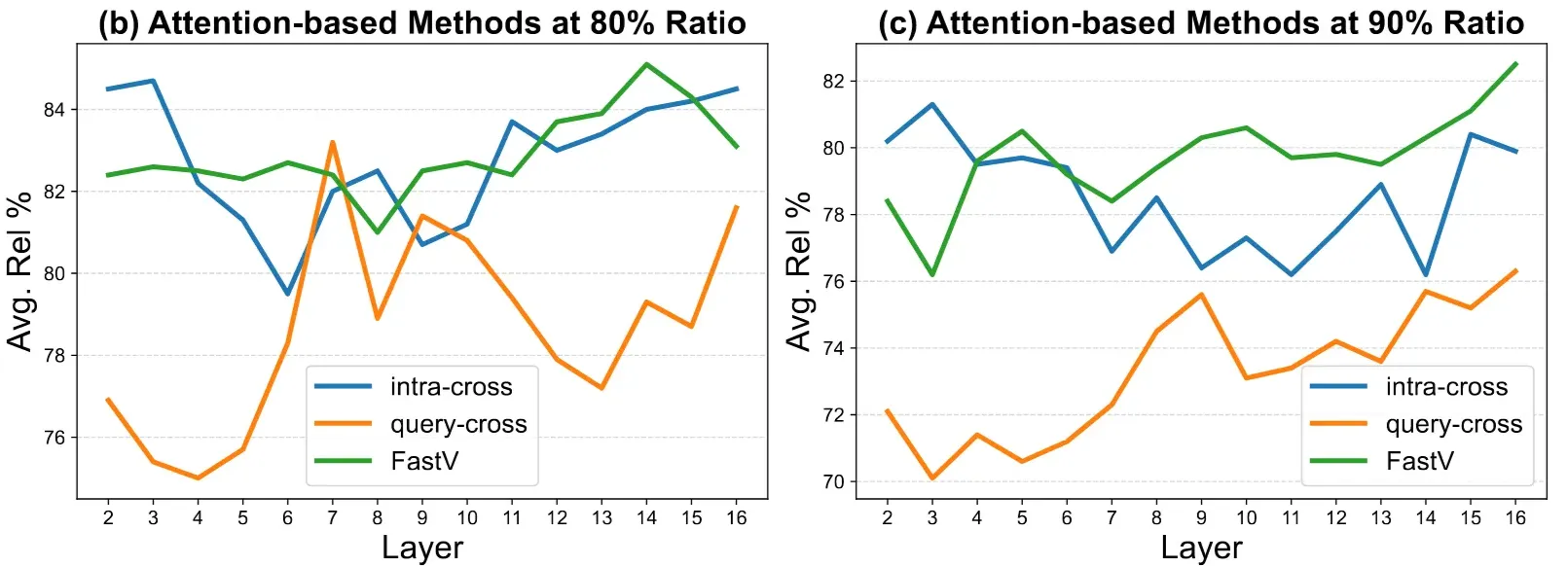
- 이 그래프에서 봐야할 Query-cross
- query sample의 모든 토큰이 image token에 주는 attention을 기준으로 한 pruning 신호
- “ICL에서는 결국 query가 중요하니, query가 주목하는 토큰이 중요하지 않을까?”
- 디코더에서 query-cross 기반 pruning이 shallow layer(7~10)에서 상대 성능이 좋아지는 경향
→ 논문에서 이를 perception 이후 query-guided reasoning으로의 전환 신호로 해석
“디코더의 Layer 도중에 query와의 상호작용이 커진다!”
결론
- 초기 decoder layer
- image–text perception
- local alignment 중심
- 특정 shallow layer 이후
- query가 context를 선택적으로 참조
- query-guided reasoning으로 전환
→ query가 context token 중요도를 실제로 ‘분별’하기 시작하는 지점이 존재
Decoder 이전에서는 query와 비슷해 보이는 visual token만 찾을 수 있을 뿐이다.
query 답변에 실질적으로 기여하는 token을 측정하기 어렵다!
이게 이 논문의 Key Idea이다.
기존 pruning과 결정적으로 다른 지점이 “단순히 Query랑 비교했다.” 가 아니라
query-guided reasoning이 발생하는 시점을 정확히 짚어서 pruning 위치를 분리했다는 점이다.
Diversity function은 그냥 projection 전에 Stage 0 처럼하면 어떤가?
Projection 이전에 하면 Projection 이전부터 프루닝을 해서 Projection 연산이 줄겠지만, 위험성이 있다.
기존에도 Diversity 관련 prune인 DivPrune 자체도 이 구간에서 했음.
Vision Encoder → Projector → DivPrune → Decoder
DivPrune frames image token pruning after the projector as a Max-Min diversity problem, aiming to choose a subset of tokens that maximizes diversity among the selected tokens.
projector 이후의 token들이 이미 decoder가 실제로 사용하는 embedding space에 놓이므로 cosine similarity 기반 diversity objective를 정의하는 것이 자연스러움!
→ reasoning에 기여하는 token을 남기는 것이 목표이기 때문에,
decoder embedding space 기준으로 diversity를 측정하도록 설계됨
수식은 같지만, projection으로 비선형 변환이 된다면 projection 전후로 공간에서 최근접 대표 토큰이 달라져서 선택되는 token 집합이 달라짐
Pruning Layer K = 6 (7B/8B), K = 10 (13B) 이유?
논문에 명시되어있지는 않지만, 아마도 decoder layer 수가 달라서 그정도 경계에서 실험한것으로 보입니다.
- LLaVA-Next-7B
- LLM backbone: Mistral-7B → 32 layers
- LLaVA-Next-13B
- LLM backbone: Vicuna-1.5-13B → 40 layers