| ArXiv | https://arxiv.org/abs/2507.05791 |
|---|---|
| OpenReview | https://openreview.net/forum?id=3VIPmz7iAi |
| Github Code | https://github.com/Yan98/GTA1 |
| Authors | Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, Ran Xu, Liyuan Pan, Silvio Savarese, Caiming Xiong, Junnan Li |
| Affiliation | 1Salesforce AI Research 2The Australian National University3University of Hong Kong |
Key Differentiator
GUI 에이전트에서 불필요하게 복잡해진 RL 설계를 걷어내고,
test-time compute와 정렬된 보상만으로도 SOTA가 가능함을 실험적으로 증명
Why I chose this paper?
- ICLR 2026 Accept 논문 리스트에서 GUI 검색 후 찾아봤다.
Related Work
GUI Grounding 연구 흐름
지도학습(SFT, Supervised Fine-Tuning) 기반 접근
- UI 요소의 중심 좌표 예측 방식
- 과제 정렬(objective alignment) 문제
- 실제 과제는 영역 내부 전체가 정답
- SFT는 중심에서 벗어나면 패널티 부여
- 고해상도·복잡 GUI에서 일반화 성능 저하
강화학습(RL, 특히 GRPO) 기반 접근
- 일반적인 설계 패턴
- 모델이 “thinking”(Chain-of-Thought) 생성
- 이후 좌표 예측
- format reward + click reward 결합
- 확장 방향
- 일부 연구는 바운딩 박스 예측(IoU reward) 까지 추가
- 하지만, 명시적 “thinking”이 GUI grounding 성능을 개선하지 않거나 오히려 정확도를 저해하는 경우 존재
- GUI grounding은 추론 문제(reasoning problem)가 아니라 정확한 위치 예측(perception-aligned task) 성격이라서
GUI Agent 아키텍처 계열
Two-stage GUI Agent
planner: 강력한 멀티모달 LLM
grounding model: 좌표 예측 담당
→ 다른 모듈로 분리
- 장점
- 모듈화로 인한 해석 용이성
- grounding 성능 개선 연구에 집중 가능
Native(end-to-end) GUI Agent
: perception, memory, planning, action을 하나의 end-to-end 시스템으로 통합
- long-context 유지, 과거 행동 이력 관리가 중요함
- sliding window 혹은 텍스트 요약 기반 trajectory 관리로 완화.
- OSWorld 같은 동적·현실적 벤치마크에서 강력한 성능
이 논문의 문제 제기
- two-stage 방식도 동적 환경에서 충분히 경쟁력 있음
- end-to-end가 유일한 해법이라는 가정에 대한 반례 제시
Method
- 문제: GUI 환경은 비가역적
- 전체 행동 시퀀스를 사전에 lookahead하기 어려움
- 단일 행동 선택 실패가 누적 오류로 이어질 가능성 존재
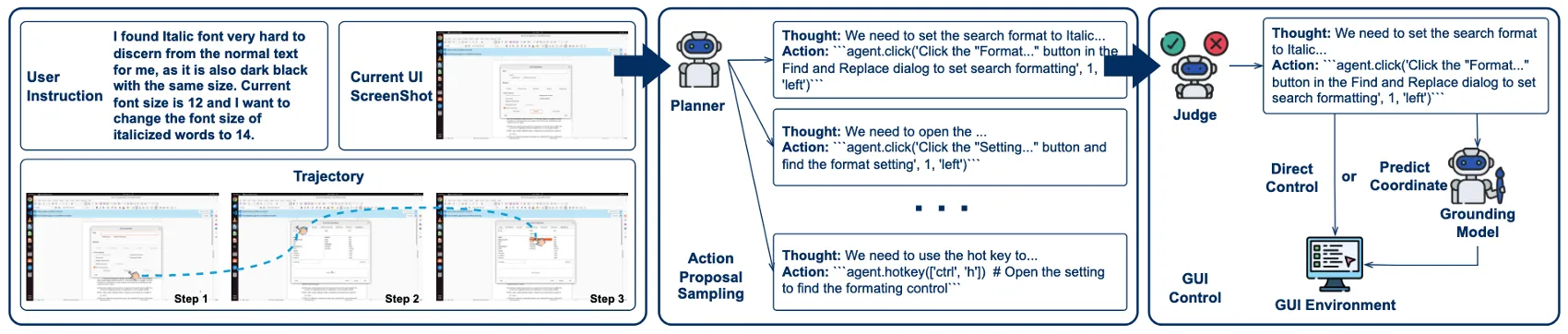
GTA1은 Native가 아닌 two-stage GUI agent 구조를 유지하면서,
각 단계의 취약점을 test-time scaling과 RL grounding으로 보완
- Planner (행동 제안 생성기)
- 멀티모달 언어 모델 기반
- 현재 UI 상태와 사용자 지시를 입력으로 받아
다음 행동 후보(action proposal)를 생성
- Judge Model (행동 선택기)
- planner가 생성한 복수의 행동 후보 중 하나를 선택
- 현재 UI 상태 + 사용자 목표를 기준으로 평가
- Grounding Model (좌표 예측기)
- 선택된 행동을 실제 GUI 좌표로 변환
- 강화학습으로 학습된 클릭 기반 모델
- GTA1
- 각 단계에서 다수의 행동 제안을 샘플링
- test-time에서만 계산량을 증가시켜 계획 선택의 강건성을 확보
- 중요한 점
- 학습 단계(training-time) 변경 최소화
- inference 단계(test-time)에서만 확장
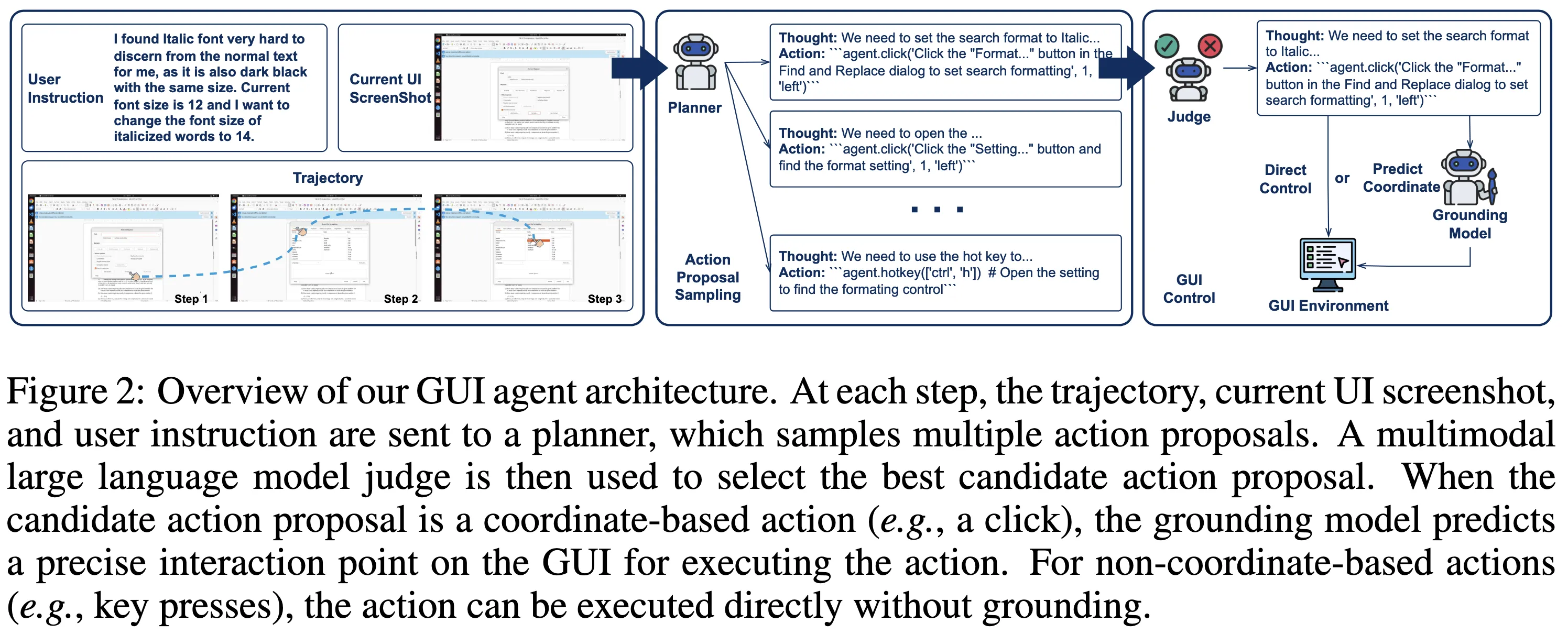
Test-time Scaling for Planning
문제: 각 단계에서 단 하나의 행동 선택은 초기 오류가 전체 실패로 이어지는 구조
각 타임스텝마다
- 행동 제안을 하나가 아니라 여러 개 생성
- test-time에서만 계산량을 늘려 선택 안정성 확보
- Planner: 동일 입력에서 N개의 행동 제안 샘플링
- Judge model: 현재 UI 상태와 사용자 목표 기준, 행동 후보 간 상대적 선호 비교
- 선택된 행동만 실제 실행
- 전체 시퀀스 최적화가 아닌 현재 단계 실패를 피하는 선택 문제
- lookahead 없이도 local robustness 확보
- cascading failure 감소
- 다양한 planner, 모델 크기와 호환
- 실제 GUI 환경에서 안정적 수행
→ GUI planning에서는 “미래를 정확히 예측하는 능력”보다 “현재 단계에서의 선택 안정성”이 더 중요하다!
GTA1은 two-stage GUI 에이전트 구조를 유지한 채, 각 단계에서 다수의 행동 제안을 생성하고 test-time에서 판별 모델로 선택하는 방식으로, lookahead 없이도 계획 안정성을 확보하는 planning 전략을 제안
Reinforcement Learning for GUI Grounding
Data Cleaning
실제 화면에서는 렌더링 지연, 타이밍 mismatch → bbox가 시각적으로 엉뚱한 위치를 가리키는 경우가 있음.
annotated bbox가 OmniParser가 감지한 실제 UI 요소들 중 하나라도 충분히 겹치지 않으면 그 데이터 샘플을 버리기 (실험에서 τ = 0.3 사용함)
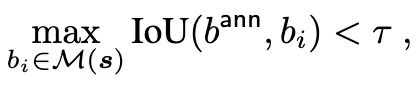
b_i : OmniPARSER가 감지한 UI
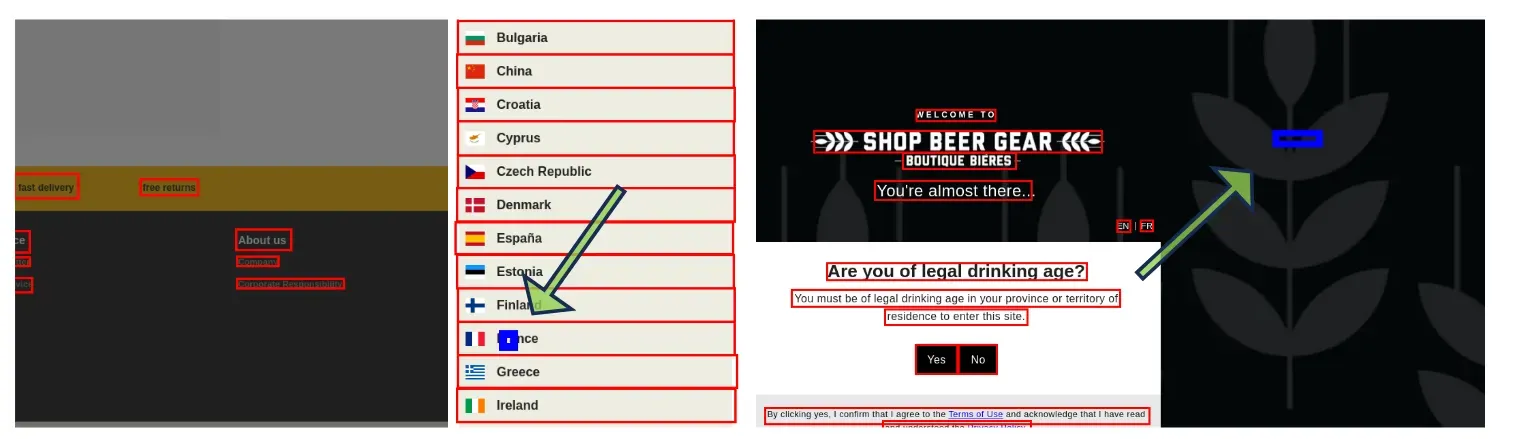
Training
- Chain-of-Thought 제거
- 기존 RL grounding: 좌표 예측 전에 reasoning / thinking / 설명 텍스트 생성, format reward로 “생각을 잘 썼는지”도 평가
- thinking 토큰, format reward 제거, 좌표 결과로만 학습 → 추론은 불필요한 노이즈다!
- 바운딩 박스, 중심점 예측, 거리 기반 보상 제거
- 기존: 중심점 회귀 손실 사용하거나 바운딩 박스 예측 + IoU 보상 추가 → “정답 구조”를 모델에 강제
- 이 논문: 모두 제거 → 과제 정의에 없는 제약 제거
- 단일 보상 신호로 단순하게 변경
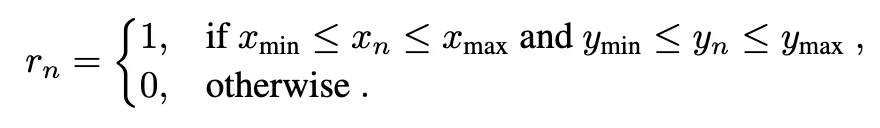
- 클릭 좌표가 목표 target UI 요소 내부면 성공, 외부면 실패
- GRPO(Group Relative Policy Optimization)
- 기존: reasoning 품질 비교에 활용 + 언어 생성 중심
- 샘플링된 “K개 좌표 중 평균 대비 더 나은 클릭인지”만 평가
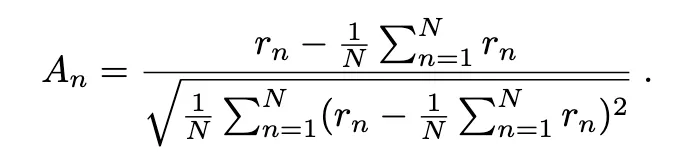
- 클릭 성공 여부가 직접 정책 개선에 반영
GUI grounding = reasoning 문제가 아니라 perception-aligned control 문제다!
Planning + Grounding 시너지
- Planning 단계
- test-time scaling으로 실패 가능성 낮은 행동 선택
- Grounding 단계
- RL 기반 좌표 예측으로 선택된 행동의 실행 성공률 극대화
- Planning은 test-time에서 넓게 보고 고르고,
- Grounding은 학습 단계에서 단순하게 정렬한다는 전략,
- lookahead 없는 GUI 환경에서도 안정적인 에이전트 동작을 가능하게 하는 설계
Experiment
| 구분 | 내용 |
|---|---|
| 에이전트 구조 | Two-stage GUI agent 구조 사용 |
| Planner | 멀티모달 LLM 기반 행동 제안 생성 모델 |
| Planning 전략 | Test-time scaling 적용, 매 step마다 복수 action proposal 샘플링 |
| Judge model | planner가 생성한 action proposal 중 상대적 선호 기준으로 선택 |
| Grounding model | RL 기반 좌표 예측 모델, 클릭 성공 여부만 사용 |
| 데이터셋 | Aria-UI 포함 curated open-source GUI 데이터 |
GTA1의 backbone
- GTA1-7B: UI-TARS-1.5-7B를 base로 초기화한 뒤 GRPO로 학습하는 구성
- GTA1-32B: OpenCUA-32B를 base로 초기화한 뒤 GRPO로 학습하는 구성
GUI Grounding Performance
RL 기반 grounding 설계 검증 (planning 영향 없이, 순수 grounding 성능만 비교)
- thinking을 제거했음에도 오히려 정확도가 더 높음
- 고해상도 UI일수록 성능 격차 확대
→ GUI grounding은 reasoning 품질이 아니라 좌표 결과와 직접 정렬된 보상 설계가 성능효과를 보여준다!
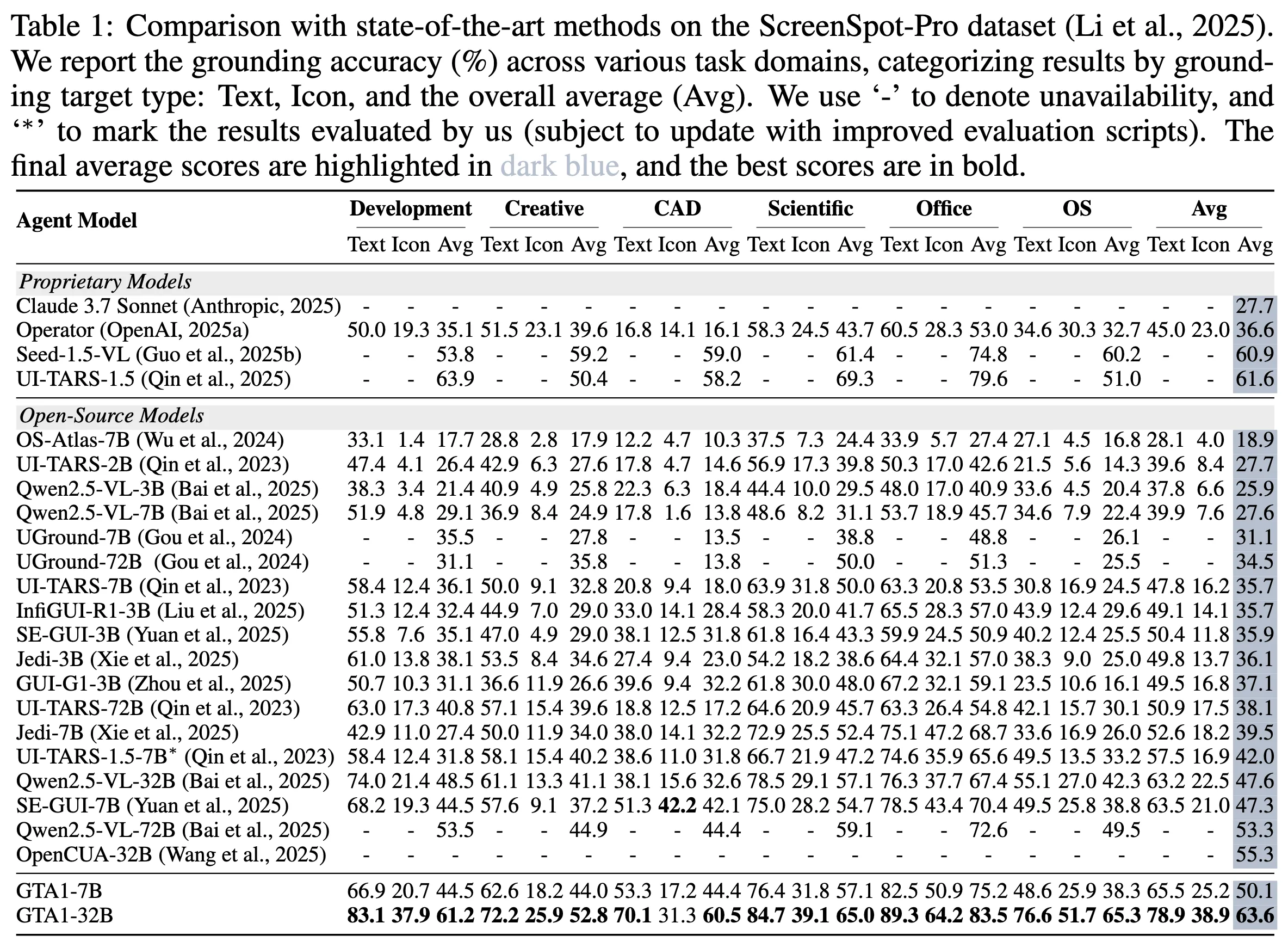
End-to-End GUI Agent Performance
- 기존 two-stage 에이전트 대비 엄청난 향상
- native가 강하다는 요즘 분위기를 two-stage로 이김
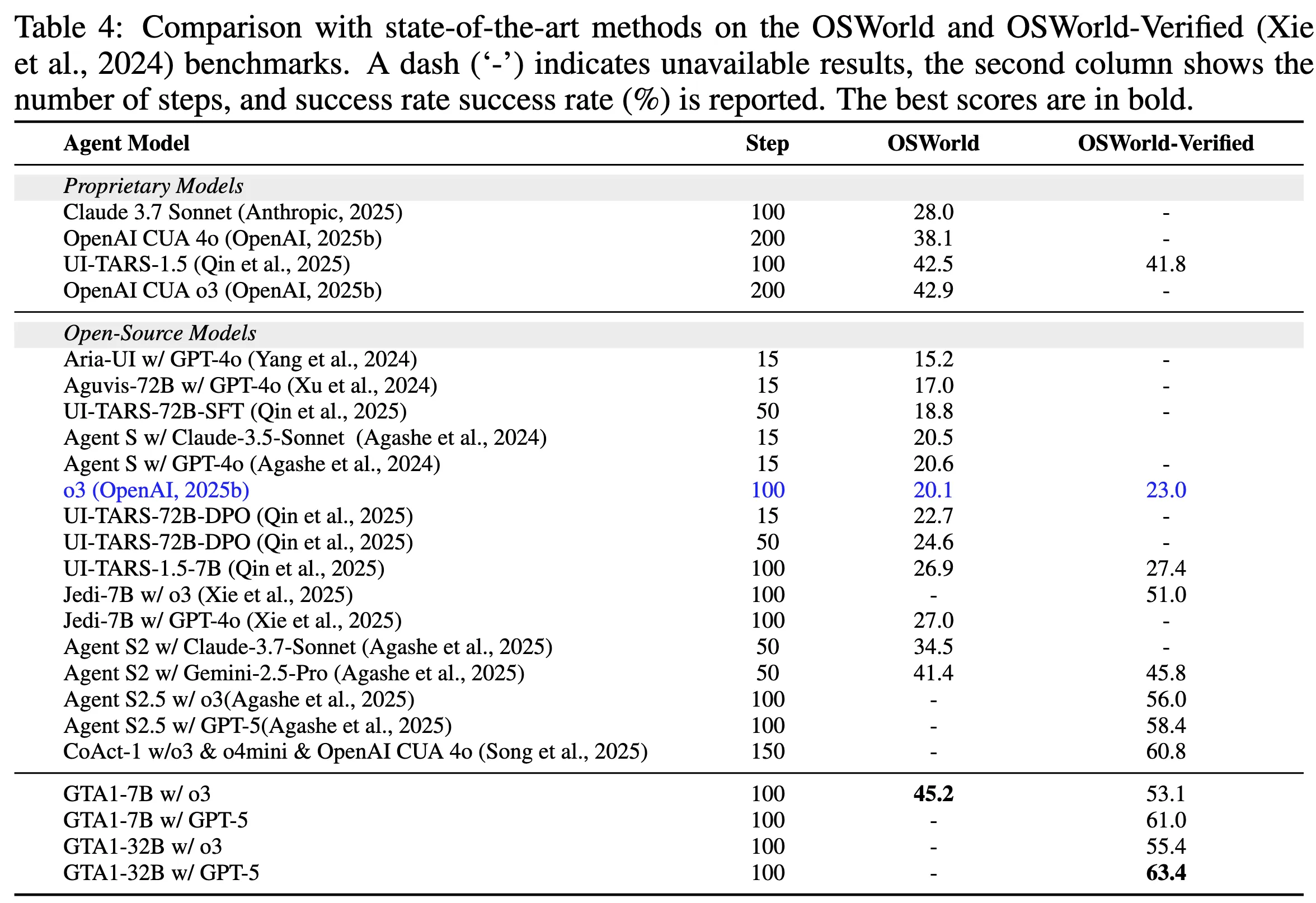
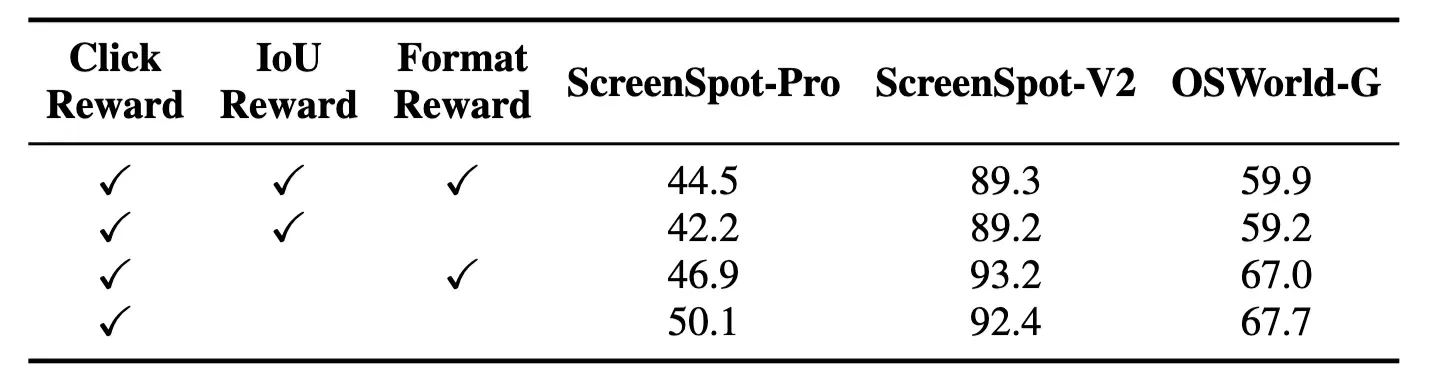
Ablation
- Click reward: 예측 좌표가 타깃 요소 bbox 안에 들어가면 성공 보상
- IoU reward: 타깃 요소 bbox 자체를 맞추도록 유도하는 보상
- Format reward: 예측 전에 “thinking”을 강제하는 보상(포맷 제약)
→ Click reward만 쓰는 조합이 좋다!
Thinking 쓰는게 ScreenSpot-V2에서 좋긴 함.
Thinking이 체계적 reasoning 이득이라기보다는 학습 불안정성이 늘어난다라고 해석.
하지만, dynamic 환경 + trajectory/goal 제공이 필요한 AndroidWorld에서는 task success rate가 39% → 44%로 증가했다는 관찰 (표는 없고 말로)
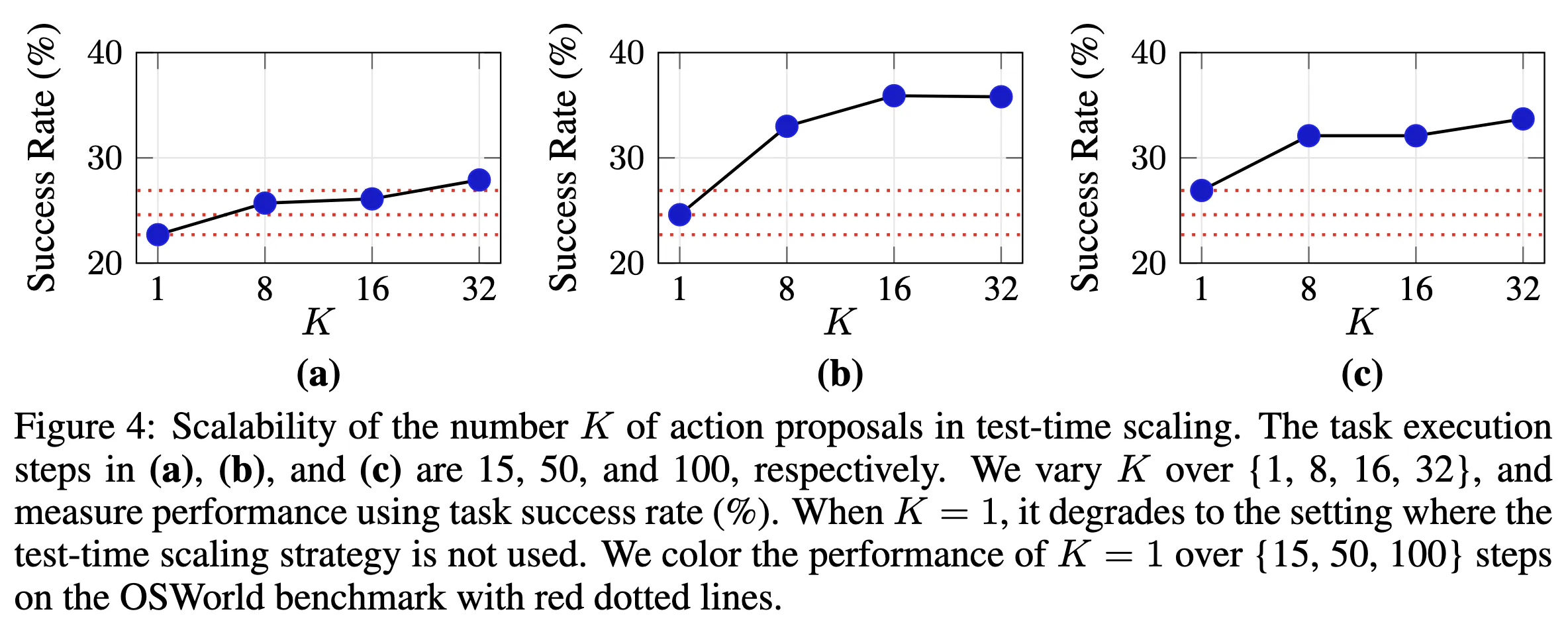
test-time scaling에서 action proposal 개수 K를 늘릴 때 성공률이 어떻게 변하는지 보여주는 그림 구성
- K 증가에 따라 성공률이 상승하는 구간 존재
- test-time compute로 robustness 확보 주장 보여주기
Conclusion
지능형 GUI 에이전트 구축을 위한 핵심 난제 두 가지로 정리
- 큰 행동 공간에서 효과적인 계획(plan) 선택 문제
- 복잡한 인터페이스에서 정확한 그라운딩(grounding) 문제
- 전략 1: Planning용 test-time scaling
- 매 스텝에서 단일 제안에 고정하지 않고 여러 action proposal을 동시 샘플링
- 멀티모달 LLM judge가 그중 가장 적절한 제안 선택
- 전략 2: RL 기반 grounding
- 타깃 요소 클릭 성공을 직접 보상하는 단순 RL 최적화
- 기존 방식이 강제하던 명시적 “thinking”을 우회하는 설계
- 표준 GUI grounding 벤치마크에서 SOTA 달성
- planner와 결합한 실제 GUI task execution에서도 견고한 동작을 확인
- 위 두 전략 결합이 “계획 안정성 + 그라운딩 정렬”을 동시에 끌어올린다는 메시지
Limitation & Future Work
grounding 모델이 시각적 선택이 아닌 “조작, 편집” 성격의 task에서는 여전히 취약
개인적인 의견
이건 계산량을 늘리고, 정확도를 올린 Tradeoff
최근에 나온 MAI-UI가 압도적으로 이김.
Two-stage GUI agent로도 native GUI agent를 이긴다는 증명 바로 깨짐.
OpenReview 정리
강점
- planning과 grounding을 각각 “왜 복잡할 필요가 없는지” 설득한 점
- thinking 제거, click-only reward 등 설계 선택의 명확성
novelty는 기술 자체보다 설계 판단과 실험적 증명에 있음
리뷰어들의 인식
- test-time scaling은 본질적으로 compute–performance tradeoff
- K 증가에 따라 토큰 비용·지연(latency)이 증가 → Dynamic K 필요
dynamic UI(AndroidWorld 등)에서는 thinking이 일관되게 이득을 주는 경향 존재
- “thinking은 필요 없다”가 아니라
- 언제, 어떤 조건에서 필요한지가 아직 열려 있는 문제
- grounding 모델이 시각적 선택이 아닌 “조작/편집” 성격의 task에서는 여전히 취약
이 논문은 새로운 알고리즘을 제시했다기보다, GUI 에이전트에서 불필요하게 복잡해진 설계를 걷어내고, test-time compute와 정렬된 보상만으로도 SOTA가 가능함을 실험적으로 증명한 연구로 평가
Q&A
논문 Presentation 발표 중 제대로 답변 못한 Q&A
trajectory에 이미지까지 쓰는건가?
GTA1 모델에서는 image를 사용하는지 논문에서 정확히 명시하지는 않았습니다.
Github Repository 탐색
GTA1 레포는 주로 어떻게 학습할것인가에 대한 레포 기반이라 해당 내용이 없습니다.
오히려, OSWorld 쪽 레포에 inference 파일이 들어있어 발견했습니다.
OSWorld/mm_agents/gta1/gta1_agent.py
predict 메서드 (라인 1226-1432):
pythonself.actions.append([plan_code]) self.observations.append(obs) # obs에는 screenshot (bytes)가 포함됨 self.thoughts.append(thought) self.observation_captions.append(observation_caption)
Planner에게 전달 (라인 1244-1298):
python# Determine which observations to include images for (only most recent ones) obs_start_idx = max(0, len(self.observations) - self.max_image_history_length) # Add all thought and action history for i in range(len(self.thoughts)): # For recent steps, include the actual screenshot if i >= obs_start_idx: messages.append({ "role": "user", "content": [{ "type": "image_url", "image_url": { "url": f"data:image/png;base64,{encode_image(self.observations[i]['screenshot'])}", "detail": "high" }, }] })
- 최근
max_image_history_length(기본값 5) 개의 trajectory step에 대해서만 실제 이미지를 포함
- 이미지는 base64로 인코딩되어 image_url 형태로 전송
- 오래된 history는 텍스트(observation caption)만 포함
→ 모든 이미지는 넣지 않고, 기본값 5개의 이미지를 넣습니다.
다만 텍스트로는 오래된 히스토리까지 넣습니다.
참고로, 이후 나온 MAI UI도 현재 제외 최대 2개의 이미지까지 넣는 듯 합니다.
- 최근
history_n - 1개의 이미지만 선택
pythondefault_conf = { "history_n": 3, # 기본값: 최근 3개만 ... }
Chain of Thought는 RL에서만 빼는건가?
thinking token 등을 제거한다고 한건, RL 메소드 설명에서가 맞습니다.
RL로 학습하는 grounding model의 출력 공간에서 thinking token 제거
그대로인 것
- planner나 judge가 내부적으로 reasoning을 쓰는 것
- inference 시 텍스트 reasoning을 쓰는 것
pythonthought_messages = f"Step {i+1} Thought:\n{self.thoughts[i]}" messages.append({ "role": "assistant", "content": [{ "type": "text", "text": thought_messages + "\n" + action_messages }] })
grpo에서는 RL에서 이렇게 단순히 좌표만 출력
pythonSYSTEM_PROMPT = ''' You are an expert UI element locator. Given a GUI image and a user's element description, provide the coordinates of the specified element as a single (x,y) point. The image resolution is height {height} and width {width}. For elements with area, return the center point. Output the coordinate pair exactly: (x,y) '''
format reward 함수 (ablation용, 이걸 사용하면 옵션으로 thinking까지 해서 함)
- 논문에서도 아직 복잡한 task에서 planning을 위해 필요한 경우도 있다고 함.
pythondef format_reward(completions, **kwargs): """Reward function that checks if the completion has a specific format.""" pattern = r" <div class="think">.*?</div> \s*<answer>\(\d+,\s*\d+\)</answer>" # ...
느낀점
여태까지 당연하게 여겨졌던 RL 메소드를 부수는 좋은 아이디어라고 생각했다.
또한, 모델까지 만들어서 배포했고, 이 당시 SOTA였기 때문에 ICLR 학회에 붙은 것 같다.
물론 금방 MAI-UI가 압도적으로 나오면서 아쉽게 되었고, 이 논문에서 모델을 활용해서 더 발전은 하지 못할 것 같다.
여태까지 당연하게 여겨온 복잡한 메소드를 간단하게 함으로서 오히려 성능을 높일 수도 있다는 좋은 아이디어를 알게 되어 좋았다.
당연하게 여겨지는 것을 바꿔야 노벨티 있는 논문이 나오는 것 같다.