| ArXiv | http://arxiv.org/abs/2412.16491 |
|---|---|
| Authors | Seungdong Yoa, Seungjun Lee, Hyeseung Cho, Bumsoo Kim, Woohyung Lim |
| Affiliation | LG AI Research, Chung-ang University |
Key Differentiator
Attention 점수가 낮은 Non-sementic한 Token끼리만 Merging
→ 최대한 Token Merging에서 의미있는 것들이 Merge되지 않도록 Token Reduction
Why I chose this paper?
- 우리나라 기업이 내는 논문을 읽고싶었다.
- 내가 최근에 제출했던 Efficient GUI Grounding 논문의 후속연구를 Token 기반으로 확장하고 싶었다.
Abstract
Vision Transformer는 모든 패치를 토큰으로 처리하기 때문에 계산량이 큼
→ 기존 연구들은 토큰을 제거(pruning) 하거나 합치기(merging)
→ 각 토큰이 의미를 충분히 담고 있지 않아서 의미 없는 토큰을 단순히 제거하거나 섞으면 오히려 정보 손실이 큼
이 논문은 ‘ImagePiece’ 라는 새로운 재토크나이제이션(re-tokenization) 방식을 제안
WordPiece tokenizer처럼 이미지 안의 의미 없는 작은 패치들을 합쳐서 의미 있는 단위가 될 때까지 묶는 방식
- local coherence 모듈: 인접한 패치들의 유사성을 높여, 서로 의미를 형성하도록 도움
- 이렇게 만들어진 새로운 “의미 있는 토큰”만 Transformer에 남기고, 끝까지 의미가 없는 토큰은 버린다.
결과
- DeiT-S 모델 기준 추론 속도 54% 향상 (약 1.5배 빠름)
- 동시에 ImageNet 정확도 0.39% 향상
- 극단적인 속도 조건(251% 가속)에서도 기존 방식보다 정확도가 8% 이상 높음
Preliminary
Vision Transformer(ViT)
- Transformer는 원래 NLP용 모델이지만,
이미지에도 적용되면서 Vision Transformer(ViT) 가 등장 (Dosovitskiy et al., 2021)
- 이미지를 정사각형 패치(p×p) 로 나누고, 각 패치를 하나의 토큰(token) 으로 변환해 Transformer에 입력
- 224×224 이미지, 패치 크기 16×16 → 개의 토큰 생성
여기에 [CLS] 토큰을 추가해 총 197개의 토큰이 Transformer 입력
Token Importance (토큰 중요도 평가)
- ViT 내부에서는 [CLS] 토큰이 전체 이미지의 전역 정보를 요약하는 역할을 함.
- 각 토큰의 중요도는 [CLS] 토큰이 해당 토큰에 얼마나 주의를 두는가(attention) 로 측정
- : [CLS] 토큰의 query 벡터
- : 전체 토큰의 key, value 행렬
- : 각 토큰이 [CLS]에 의해 얼마나 중요하게 여겨지는지 나타내는 attention score
→ 이 attention score 값이 높을수록, 그 토큰은 전체 이미지 의미를 구성하는 데 더 중요함을 의미.
- 각 토큰은 패치 임베딩(embedding) + 위치 임베딩(positional embedding) 을 포함하여
Self-Attention으로 전역 정보를 학습함.
- 즉, NLP에서의 “단어 토큰” → ViT에서는 “이미지 패치 토큰”
그러나 두 분야는 토큰의 의미(semantic structure) 측면에서 큰 차이가 있음
| 구분 | NLP (WordPiece 등) | ViT (Patch Token) |
|---|---|---|
| 입력 단위 | 단어 또는 의미 있는 서브워드 | 16×16 픽셀 패치 |
| 토큰 의미 | 대부분 의미 있음 | 많은 패치는 배경 등, 의미 없음 |
| 결과적 문제 | 없음 | 정보가 희박하고 중복 많음 |
→ ViT의 효율성 문제는 “의미 없는 토큰이 너무 많음” 에서 비롯됨.
ViT = O(N²)
Related Work (Efficient Transformer)
(1) Efficient Attention
Self-Attention의 연산량 자체를 줄이는 접근.
Attention을 근사하거나 병렬 최적화로 속도 향상.
- Linformer (Wang et al., 2020)
- Performer (Choromanski et al., 2020)
- FlashAttention (Dao et al., 2022)
→ Attention 레벨의 최적화로 계산만 줄이고, 토큰 자체의 의미 문제는 해결하지 못함.
(2) Token Pruning (토큰 제거)
비중요 토큰을 attention score 기준으로 제거.
- DynamicViT (Rao et al., 2021): 학습된 projection layer로 토큰을 점진적으로 버림.
- EViT (Liang et al., 2022): class token에 대한 attention을 기준으로 하위 토큰 삭제.
- SPViT (Kong et al., 2022): soft selector로 중요도 계산 후 pruning.
→ 의미가 완전히 드러나지 않은 토큰(예: 버스의 일부 조각)을 너무 빨리 제거함 → 정보 손실 발생.
(3) Token Merging (토큰 병합)
비슷한 특징을 가진 토큰들을 결합(merge) 하여 수를 줄임.
- ToMe (Bolya et al., 2023): bipartite soft matching으로 가장 유사한 토큰 쌍 병합.
- Token Pooling (Marin et al., 2021): K-Means 기반 병합.
- Token Learner (Ryoo et al., 2021): MLP로 선택적 토큰 생성.
→ 비슷하지만 의미가 다르거나 중요한 토큰들까지 섞임 → 결과적으로 semantic dilution (의미 희석) 발생.
이들의 공통점!
“토큰의 의미(semanitcs)를 고려하지 않는다”
ImagePiece
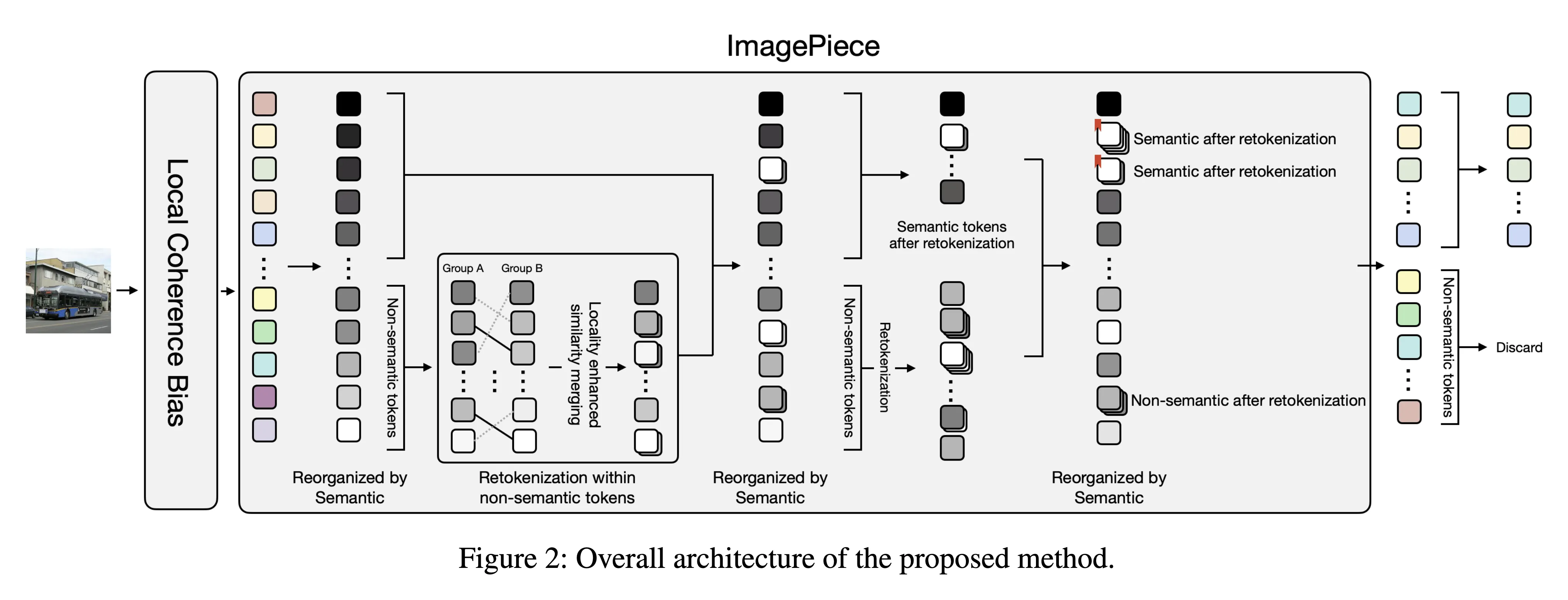
ViT의 효율화는 단순히 토큰 수를 줄이는 게 아니라,“토큰이 충분히 의미를 가질 때까지 재구성(re-tokenization)” 해야 한다.
Step I : Token Importance Evaluation
- 각 토큰이 전체 이미지 의미에 얼마나 기여하는지 평가
- [CLS] 토큰과의 attention 값 을 이용해 중요도 순위를 계산
- 중요도가 낮은 bottom-k 토큰을 후보로 지정 → “non-semantic tokens”
Step II : Re-tokenization of Non-semantic Tokens
- bottom-k 토큰들을 두 그룹(A, B)으로 나눈 뒤,
가장 유사한 쌍끼리 merge
- 병합에는 bipartite soft matching을 사용
Bipartite soft matching (Bolya et al., 2023)
“두 그룹 사이의 최적 유사도 매칭” 을 부드럽게(softly) 계산하는 알고리즘
- Bipartite structure
- 두 토큰 집합 A 와 B 가 주어졌을 때, A의 각 토큰이 B 내의 한 토큰과 연결될 확률 계산
- Soft assignment
- 각 연결의 강도 :
→ 하나의 A 토큰이 여러 B 토큰의 정보를 가중합 형태로 병합 가능
- Information preserving merge
- 새 토큰은 로 계산되어,
하드 매칭보다 더 연속적이고 손실이 적은 병합을 수행
- 새 토큰은 로 계산되어,
- Bipartite structure
Step III : Re-evaluation and Discarding
- merge된 토큰들만 attention 을 다시 계산히면서 step1, 2 반복
- 최종적으로 여전히 의미가 없으면 → 최종적으로 삭제 (prune)
Local Coherence Bias (로컬 일관성 강화 모듈)
- 이미지의 공간적 특성을 고려해, 인접한 패치들은 유사하게 인식되도록 bias를 추가
- 구체적으로 4개의 3×3 conv + 1개의 1×1 conv 를 적용해 겹치는 패치 feature 를 만듦
- 결과적으로 공간적으로 가까운 패치들은 유사도가 높아지고,
병합 과정에서 자연스럽게 같은 의미 단위로 묶임

| WordPiece (NLP) | ImagePiece (Vision) |
|---|---|
| 문장을 의미 있는 단어 단위로 분해. | 이미지를 16×16 패치로 분할. |
| “meaningful tokens” → 각 토큰이 이미 의미를 가짐. | “patch tokens” → 대부분 의미 없음(배경·하늘 등). |
| 긴 문장을 MaxMatch(최대 일치) 로 토큰화. | 의미 없는 패치들을 의미가 생길 때까지 합침. |
WordPiece는 단어를 쪼개 의미 단위를 만들고,ImagePiece는 반대로 의미 없는 조각들을 합쳐 의미 단위로 만듦
예를 들어, 파란색 패치 하나만 보면 아무 의미 없지만
주변 패치들과 합치면 ‘버스’라는 의미가 생김 → 이게 re-tokenization 의 핵심
Compatibility with Other Methods
- 재토큰화가 토큰 생성 단계에서 이뤄지므로, 그 뒤의 pruning 또는 merging 모듈과 충돌하지 않음
- 기존 Token Pruning (EViT, DynamicViT) 이나 Merging (ToMe) 방식과 결합 가능
- 오히려 re-tokenization 덕분에 초기 layer에서 의미 없는 패치가 빨리 정리되어 전체 효율이 더 좋아짐
Experiment
실험 개요
- 데이터셋: ImageNet-1k (1.2M train, 50k test)
- 기반 모델: DeiT-Ti, DeiT-S (두 가지 Vision Transformer 버전)
- 입력 크기: 224×224
- 훈련: 300 epoch / finetuning, pretraining 없음. (DeiT 논문과 동일한 설정으로 )
- NVIDIA RTX 3090
Table 1 - Token Pruning 비교 결과
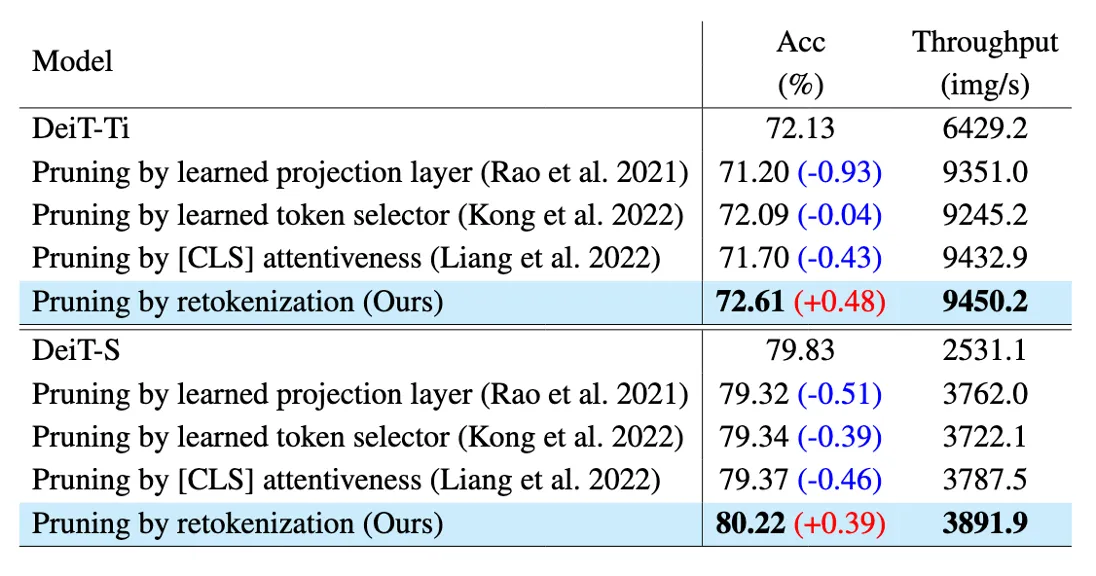
같은 keep ratio (0.7)기준으로 측정
- DynamicViT / EViT 은 토큰 제거 결정을 후반 layer에서 함 → 앞쪽 layer는 여전히 많은 토큰을 처리
- ImagePiece는 초기에 re-tokenization을 수행 → 앞 layer부터 토큰 수가 크게 줄어듦.
Table 2 - Token Merging 비교 결과
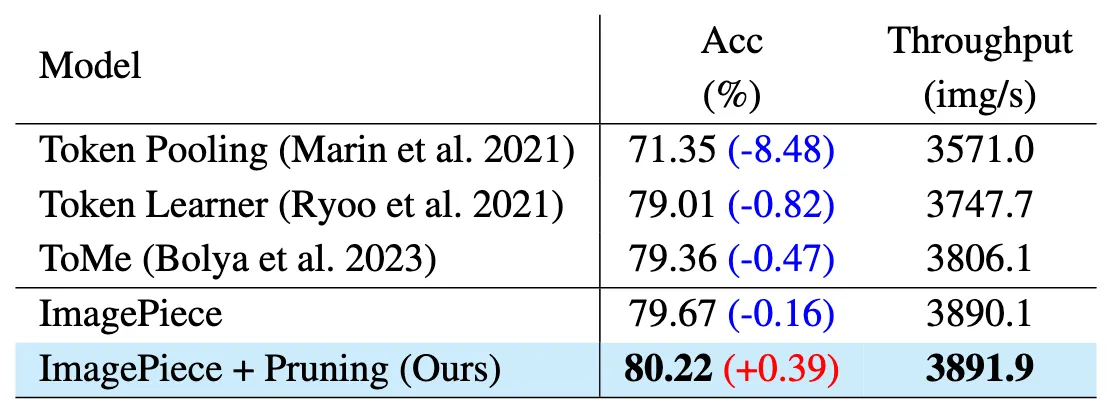
ImagePiece는 의미 없는 토큰만 병합하기 때문에 의미 있는 정보(semantic tokens)는 그대로 유지
→ 정확도 손실 거의 없음
Figure 3 - Hyper-speed Inference Experiment
이 실험은 “토큰 수를 극단적으로 줄여도 성능이 유지되는가?” 를 보는 테스트
각 모델의 keep rate (남기는 토큰 비율)을 70%, 60%, 50%, ... 로 점점 줄여가면서 측정
→ 극단적으로 빠른 추론 속도일때도 정확도 많이 보존

같은 Acc 기준으로 비교

- ImagePiece는 전체 토큰의 13%만 남기고도 정확도를 유지
- 동일한 성능 기준에서 30% 이상 빠른 추론 속도를 달성
- “의미 없는 토큰을 더 정확히 식별해 버리기 때문”
Table 4 - Random Masking Noise Robustness
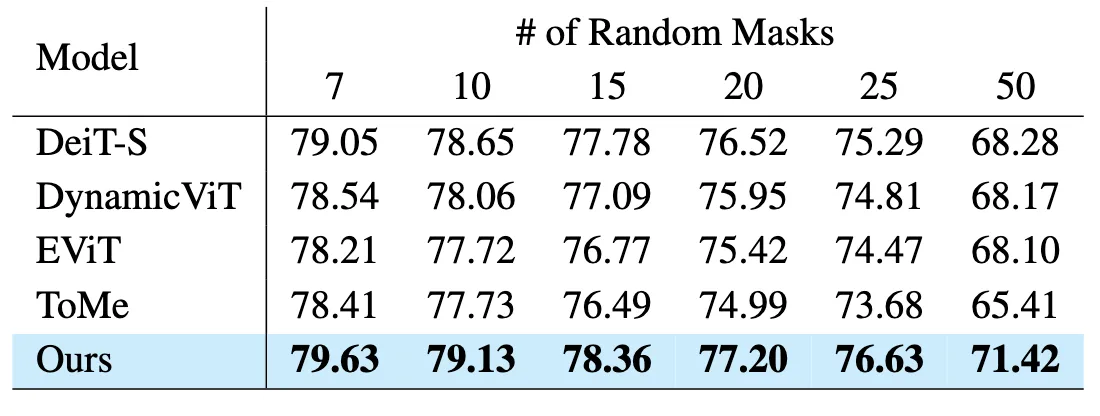
노이즈나 가려진 영역에 대한 견고성(robustness) 검증
- 테스트 이미지에 무작위 16×16 마스크 7~50개 추가
- “의미 단위로 묶인 토큰이 더 견고한 global representation”
Table 5 - Token Attentiveness 변화
“의미 없는 토큰도 병합 후 의미가 생기면 다시 중요해진다”

- 이전 layer에서 inattentive(비중요)로 판단되었던 토큰 중 다음 layer에서 attentive(중요)로 바뀐 비율
- re-tokenization 덕분에 의미 없는 토큰이 의미 단위로 병합되면서 semantic importance를 회복
Table 6 & 7 - Token Similarity
병합된 토큰 쌍(token pairs) 들의 feature cosine similarity

ToMe: layer가 깊어질수록 유사도가 떨어져 정보 희석 발생,
ImagePiece: 정보 일관성 보존
첫번째 layer에서 병합된 토큰 중 “중요 토큰” 비율

→ 기존 merging 방식은 중요한 토큰을 너무 자주 병합함.
반면 ImagePiece는 bottom-k만 병합하므로 semantic dilution 방지.
Table 8 - Local Coherence 효과

→ 공간적으로 가까운 패치끼리 의미 단위로 묶인다
| Accuracy (%) | |
|---|---|
| ImagePiece (no local bias) | 79.81 |
| Full ImagePiece (with local coherence) | 80.22 |
→ local coherence module 설계가 효과 있음.
Table 9 - Compatibility 실험
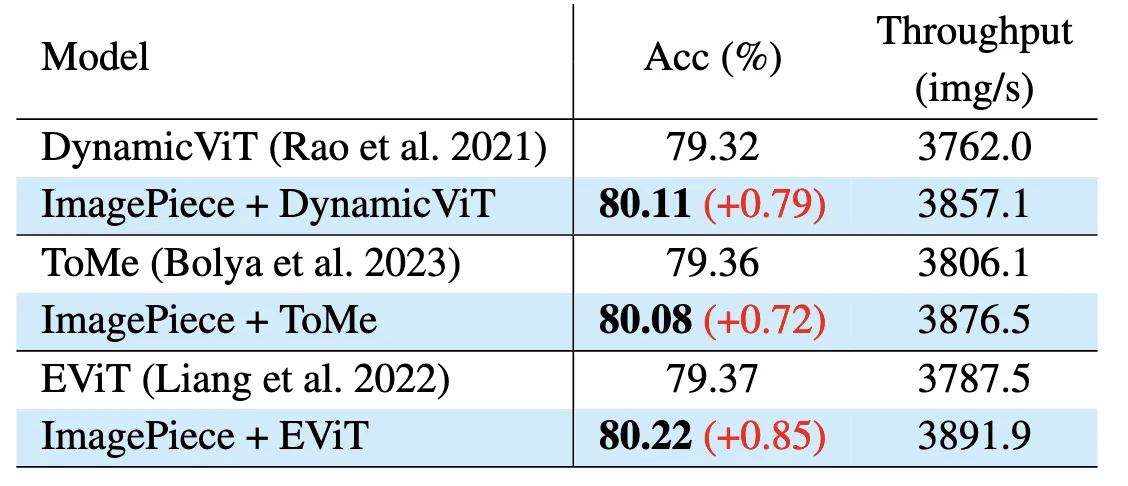
기존 pruning·merging 구조에 ImagePiece를 단순 추가해도 정확도, 속도 향상
→ 모듈형으로 삽입 가능한 확장성 높은 구조
Limitation & Future Work
논문에는 없지만 내가 생각해본 점들
Patch 크기와 구조에 민감
모델마다 최적의 Patch 크기가 다를 수 있는데, 패치 크기가 작거나 크다면 알고리즘이 잘 작동하지 않을 것 같다.
(논문에서는 16x16 사용)
→ 최근에 내가 제출한 논문에서도 이와같은 Limitation이 있었다.
future work
- Feature map 해상도에 따라 병합 granularity를 자동 조절
- Local coherence module의 receptive field를 patch size에 맞게 조정
Semantic 기준이 attention 기반
의미 정의가 attention score에만 의존
→ 복잡한 장면(다중 객체 이미지)에서는 토큰 병합이 부정확할 가능성 존재.
future work
- attention 외에도 spatial, contrastive, objectness 정보를 결합하여 토큰 의미 평가