| ArXiv | https://arxiv.org/abs/2507.22424 |
|---|---|
| Github Code | https://github.com/PineTreeWss/SpecVLA |
| Authors | Songsheng Wang, Rucheng Yu, Zhihang Yuan, Chao Yu, Feng Gao, Yu Wang, Derek F. Wong |
| Affiliation | 1 NLP2CT Lab, Department of Computer and Information Science, University of Macau 2 Infinigence AI 3 Tsinghua University 4 Zhongguancun Academy |
Key Differentiator
LLM에서 주로 이용되던 Speculative Decoding을 VLA에 사용하여서 속도 향상
SD를 naive하게 넣었을 때 발생하는 tight한 기준의 문제를 Relaxed acceptance를 사용하여 acceptance length를 늘려 VLA에 맞는 Speculative Decoding을 사용했다.
Why I chose this paper?
- 대부분의 기존 연구는 model compression이나 architecture 변경에 집중되어있는데, training 없이 decoding 전략만으로 속도를 개선한다는 점에서 좋아보여서
- simple하지만 effective한 아이디어 같아서 오히려 이걸 바탕으로 후속연구 해보고싶어서
3. Background
3.1 Vision-Language-Action (VLA) Models
VLA: image, text를 조건으로 로봇의 action sequence를 생성하는 autoregressive 모델
- Input
- visual input: 환경 이미지 또는 observation
- language input: task instruction
- multimodal fusion을 통해 unified representation 생성
- Output
- action token sequence
- 각 토큰은 로봇의 연속적인 행동(step) 또는 control signal을 의미
- Decoding 디코딩 방식
- autoregressive decoding
- 이전 action token을 기반으로 다음 action token 순차 생성
- 일반적으로 greedy decoding 사용 (low-entropy 특성 때문)
Limitation
- sequential decoding으로 인한 latency
- real-time control에 비효율적
- long horizon task에서 지연 누적 문제 발생
3.2 Speculative Decoding
작은 모델이 미리 여러 개 찍고, 큰 모델이 한 번에 검사해서 맞는 것만 빠르게 채택하는 방법
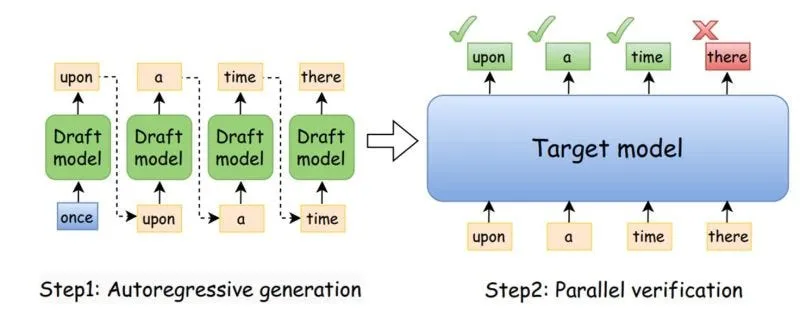
작은 draft model과 큰 verification(target) model을 함께 사용하는 decoding
- draft model이 k개의 토큰 생성
- A → B → C → D → E
- 빠르지만, 조금 부정확할 수 있음
- verification model이 해당 토큰들을 병렬적으로 평가
- 느리지만 정확함
- 병렬적으로 위 결과를 한번에 검사
- acceptance condition에 따라 일부 또는 전체 토큰 수용
Draft: A B C D E
Verification: A B X ...- A → 일치 → accept
- B → 일치 → accept
- reject된 지점부터 다시 생성 반복
- C → 불일치 → C부터 reject이니 다시 생성
장점
- 원래: 1 step → 1 토큰
- Speculative Decoding: 1 step → 여러 토큰
→ 병렬 검증을 통해 inference 가속
한계
- acceptance rate가 낮으면 효과 감소
- draft model 품질에 크게 의존
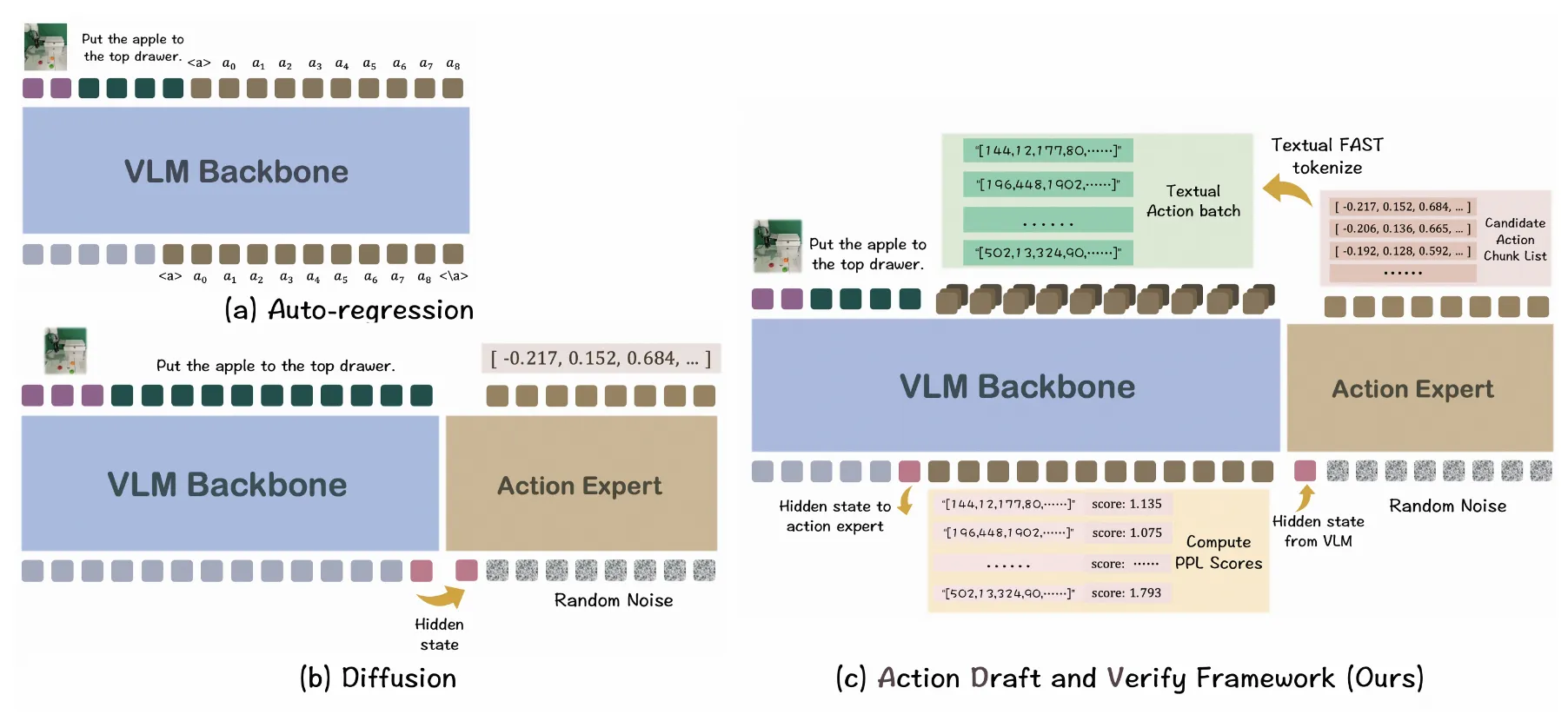
4. Method (Spec-VLA)
4.1 Overview of Spec-VLA Framework
- 목적
- VLA 모델의 autoregressive decoding latency 감소
- speculative decoding을 VLA 특성에 맞게 재설계
- draft model: lightweight VLA
- verification model: 원래의 대규모 VLA (예: OpenVLA)
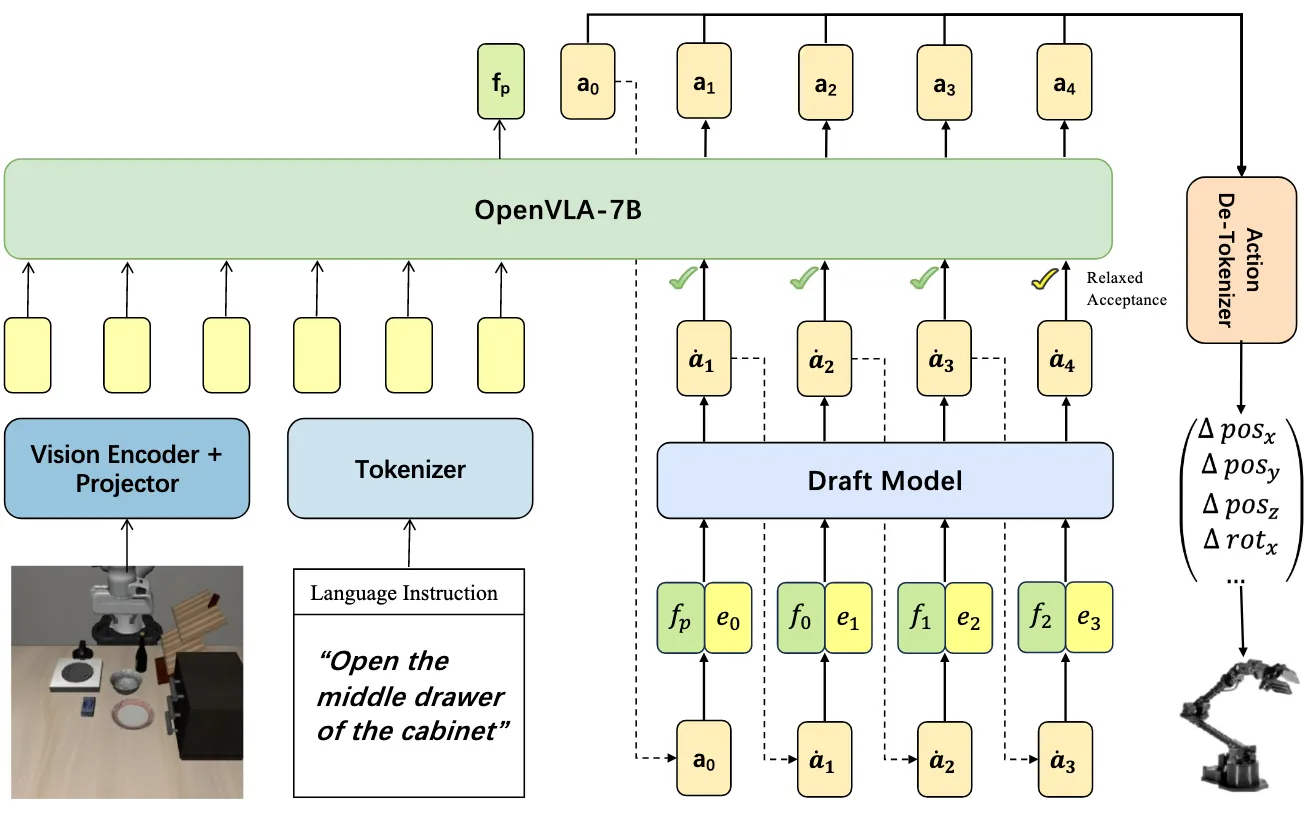
- draft model이 action token sequence를 여러 step 생성
- verification model이 해당 토큰들을 한 번의 forward pass로 병렬 검증
- acceptance rule에 따라 토큰 수용 (Relaxed Acceptance)
- accept된 토큰들을 prefix에 추가하고, reject 발생 시 해당 위치부터 다시 생성
4.2 Relaxed Acceptance for Action Tokens
- action token 간 relative distance 기반 acceptance
- 기존 LLM SD
- verification: "go to the kitchen"
- Draft: "go to the room”
- exact match 요구
- VLA에 naive하게 적용한다면?
- Verification: joint = [0.52, 1.10, -0.33]
- Draft: joint = [0.51, 1.09, -0.32]
- action token이 조금만 달라도 reject 발생
- acceptance rate가 낮음
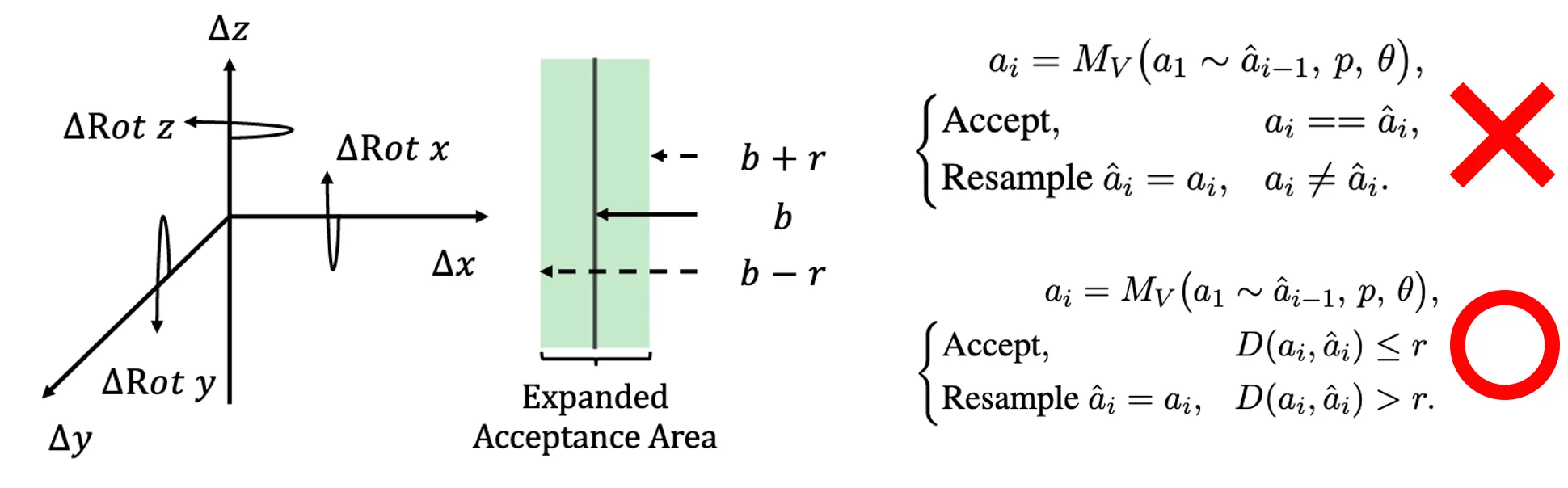
acceptance 조건
- 기존: draft token == verification token
- 제안: distance(draft, verification) < threshold
- distance: action token이 나타내는 값 사이 L2 distance or task-specific metric
기존 LLM에서의 relaxed acceptance를 그대로 접목시킨건가?
- LLM: top-k 기반 확률적 유사성
- Spec-VLA: 물리적 의미 기반 거리(metric-based similarity)
→ 그냥 relaxed acceptance 적용한게 아니라 action에 어울리는 메트릭으로 적용
- 기존 AR decoding: O(T) forward passes
- Spec-VLA: O(T / acceptance_length) forward passes
5. Experiments
5.1 Experimental Setup
Dataset: LIBERO
Verification model: finetuned OpenVLA
Draft model:
- OpenVLA를 사용하여 dataset을 재생성하고, 해당 데이터를 기반으로 draft model 학습

Eagle-2의 구조 및 구현 상속
- maximum nodes: 50
- tree depth: 4
- top-k tokens: 8개 사용하여 draft tree 구성
- 단순 linear draft가 아니라, tree 형태로 multiple candidate 생성
학습 환경
- GPU: 4 × Tesla A100 (80GB)
- batch size: 16
- training time: 약 6시간
5.2 Main Results
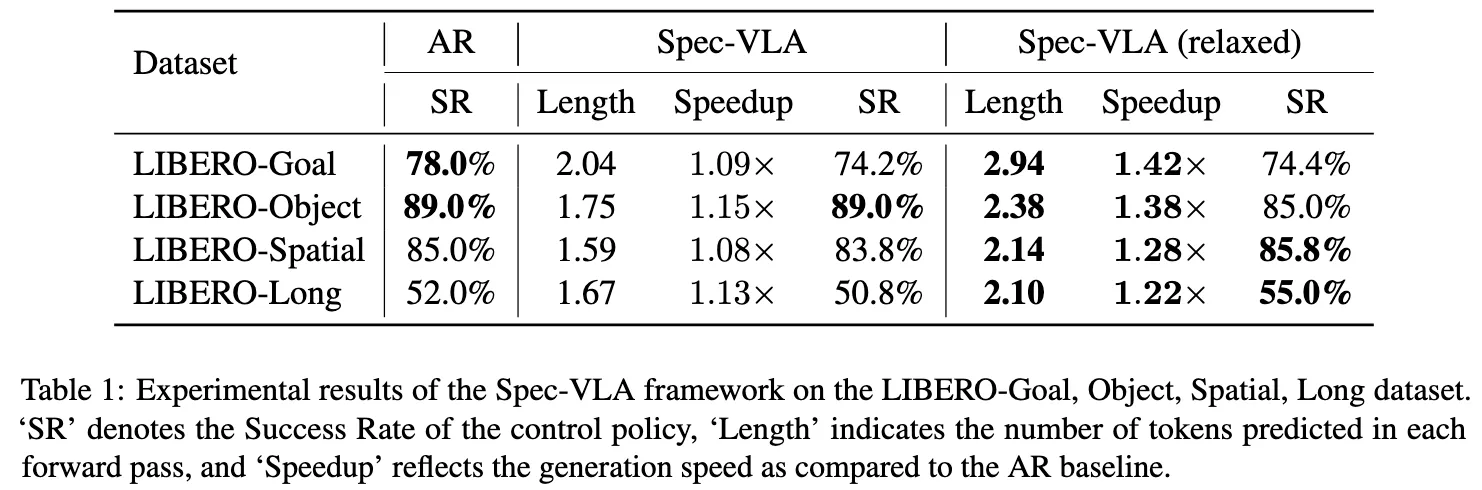
- AR decoding: O(T) forward passes
- Spec-VLA: O(T / acceptance length) forward passes
5.3 Ablation Study (Relaxed Acceptance 분석)
- relaxed acceptance가 실제로 성능 향상의 원인인지 검증
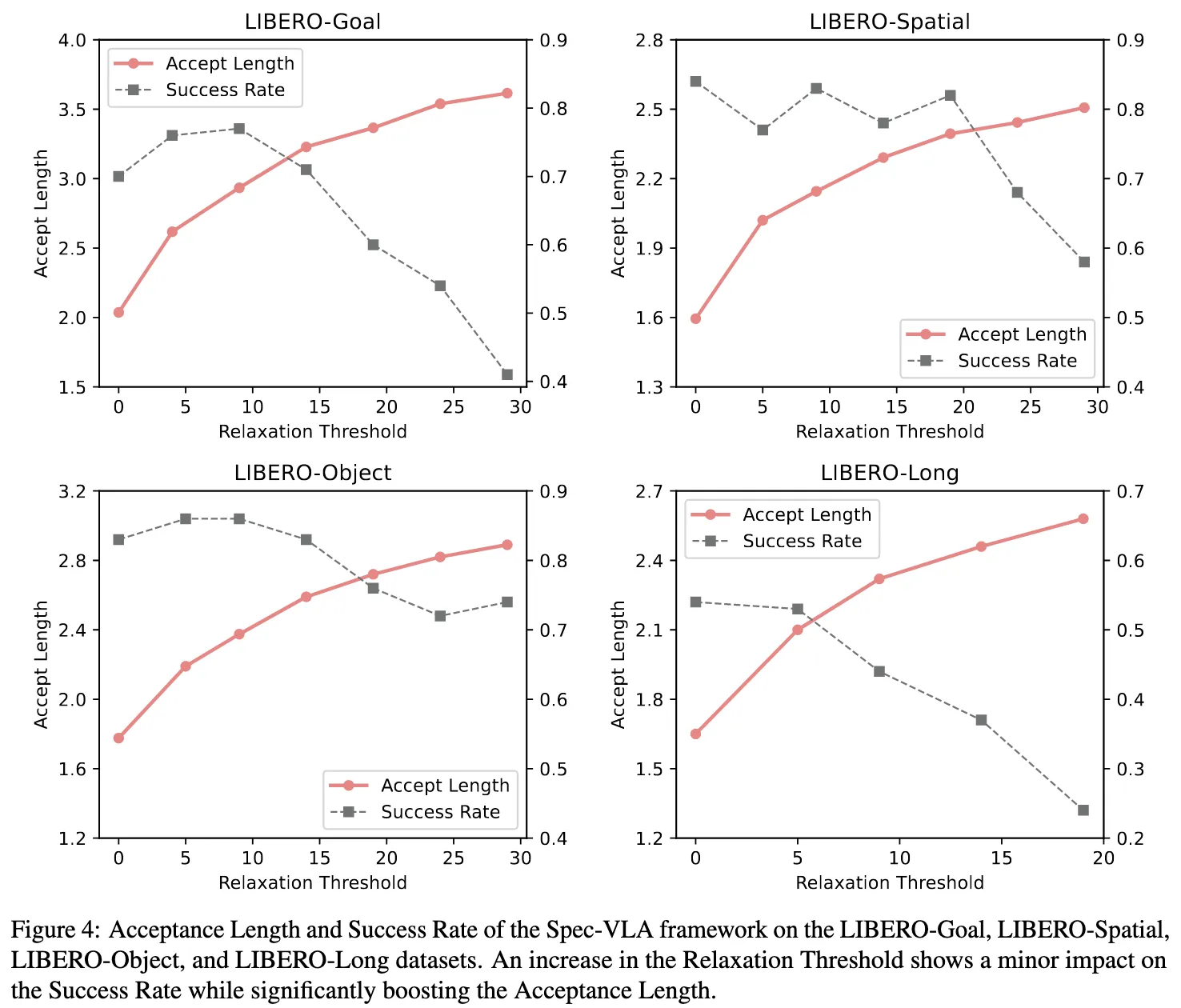
- threshold ↑ → 더 많은 token accept → forward pass 감소 → 속도 증가
- long-horizon task: error accumulation 영향 커서 Success Rate 빨리 낮아짐
→ 모델이 잘하는 task일수록 더 큰 threshold 허용 가능하다!
6. Analysis
6.1 Acceptance Length Proportion

6.2 Acceptance Length on Multiple Positions
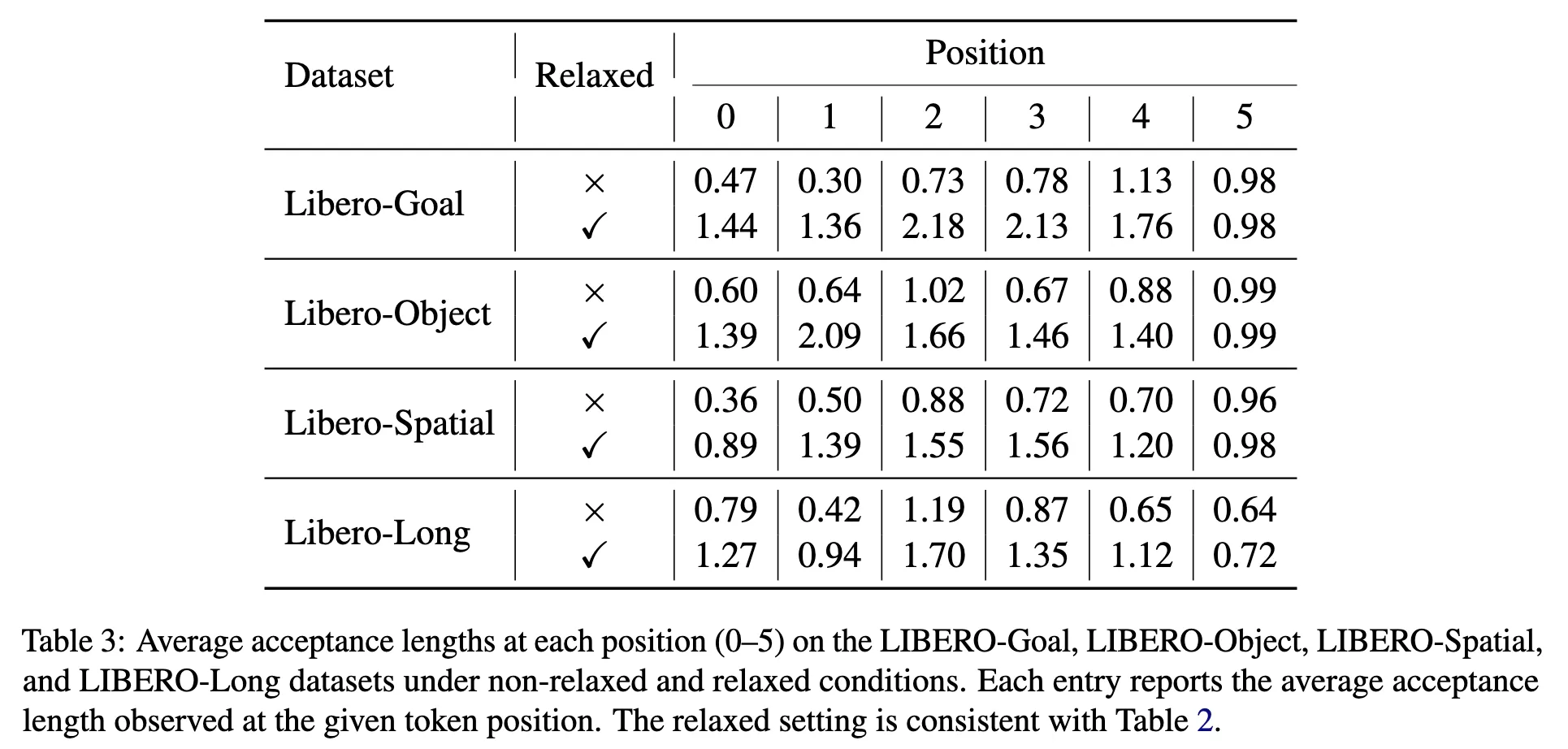
- 특정 위치에서만 좋아진 게 아니라, 전체 trajectory에서 consistently 좋아진다
6.3 Case Study

- Non-relaxed: 4번 반복 후 완성
- Relaxed
- 1st iteration: [119, 121, 109] 포함
- 2nd iteration: [98, 77, 256] 추가
- 2번만에 완성
Limitation & Future Work
- Weak Experiment
- real-world robotic setting에서 검증 없음
- LIBERO benchmark에만 의존
- generalization 한계 가능성
- No Action Chunking
- action sequence를 chunk 단위로 생성하지 않음
- token-level decoding을 유지하기 때문에 long-horizon 효율 개선에는 한계 존재
- threshold tuning 필요
- task / dataset마다 적절한 relaxation threshold 존재
- threshold 기반 heuristic 방식
- adaptive / task-aware 메커니즘 부재
논문 읽은 후…
아직까지 (26.03.24) 후속연구로 Speculative decoding 사용한게 없는가?
Spec-VLA 논문을 인용한 논문들
직접 후속 논문
DAC 2026
Sepc-VLA의 정적 acceptance threshold와 token error 발생 시 re-inference 비용 문제 제기
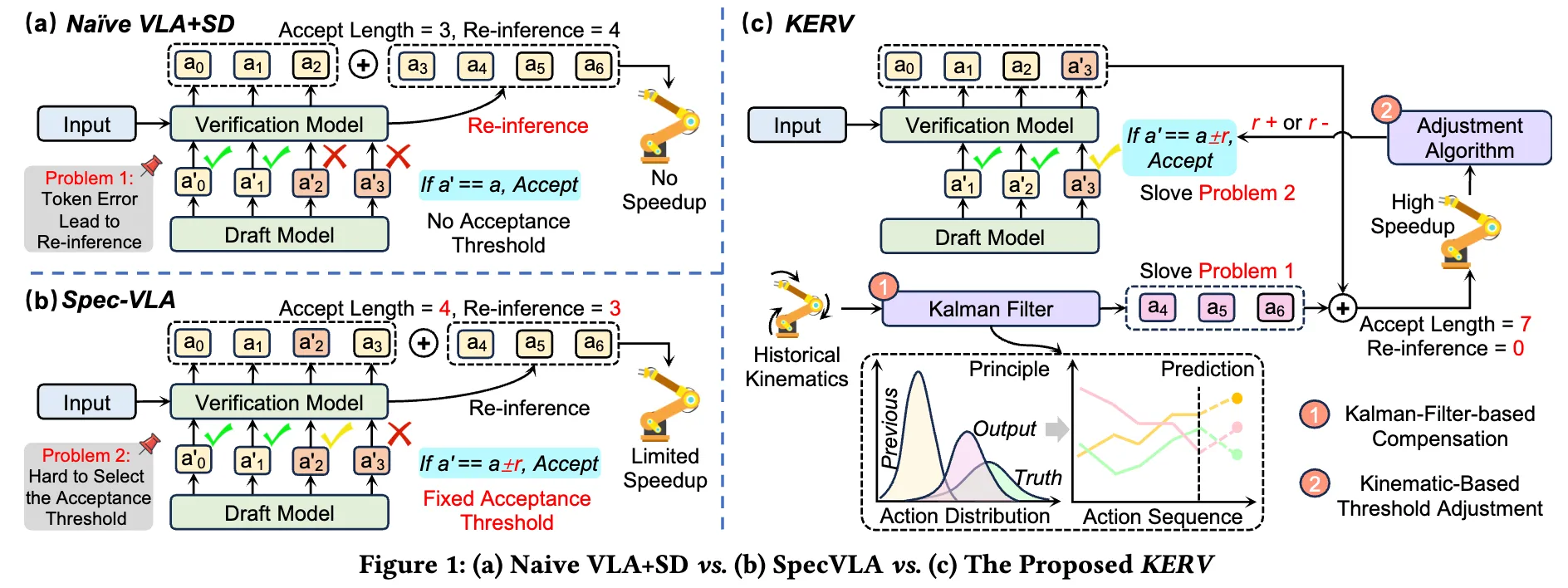
kinematics 기반 Kalman filter 보정과 dynamic threshold rectification을 도입
SpecVLA 대비 27%~37% 추가 가속과 거의 무손실 success rate를 주장
ICML 2026 제출한듯
위 KERV랑 같은 저자여서 인용도 함.
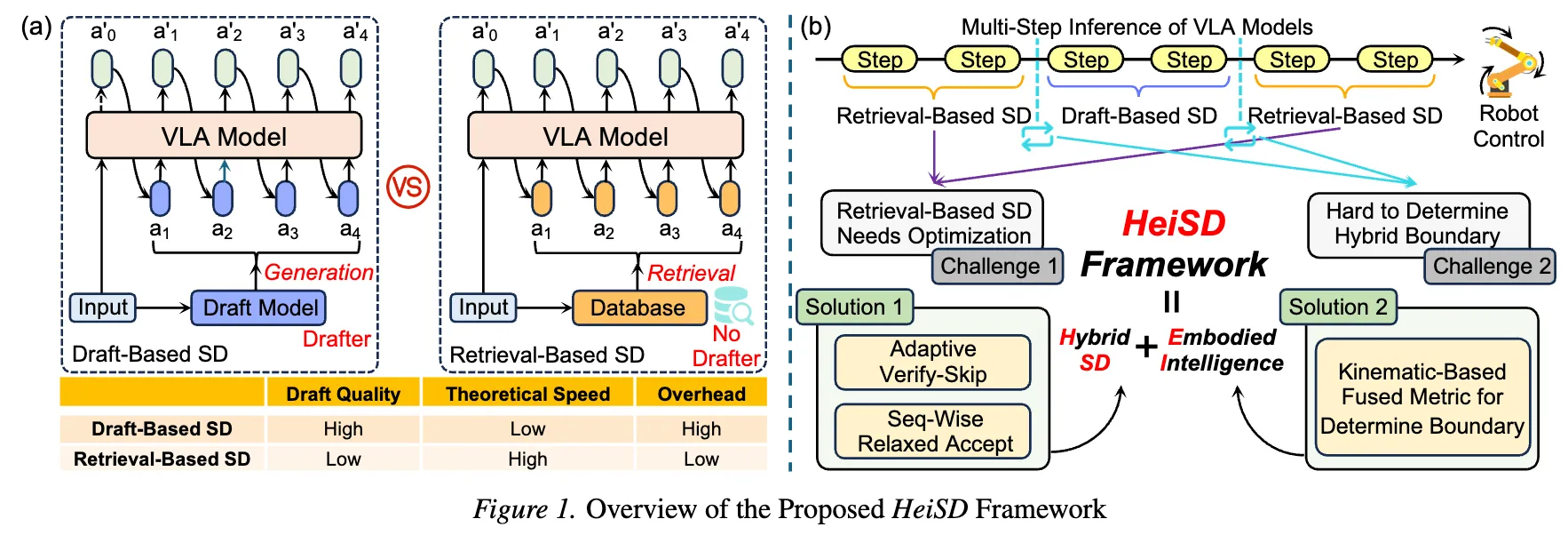
VLA용 SD를 drafter-based와 retrieval-based 두 축으로 나눠 보고, 둘을 섞는 hybrid SD를 제안
핵심 추가 요소가 verify-skip, sequence-wise relaxed acceptance, kinematic-based fused metric으로 hybrid boundary를 자동 결정하는 구조.
simulation 최대 2.45×, real-world 2.06×~2.41×
인접 확장
ICML 낸듯
Spec-VLA는 AR 모델 추론 가속이 목표이고 자기들은 AR과 diffusion의 장점 결합이 목표라고 선 긋는 구조
→ direct successor라기보다는 draft-verify 아이디어의 목적 함수 변경
token AR VLA가 아니라 video generation policy 쪽
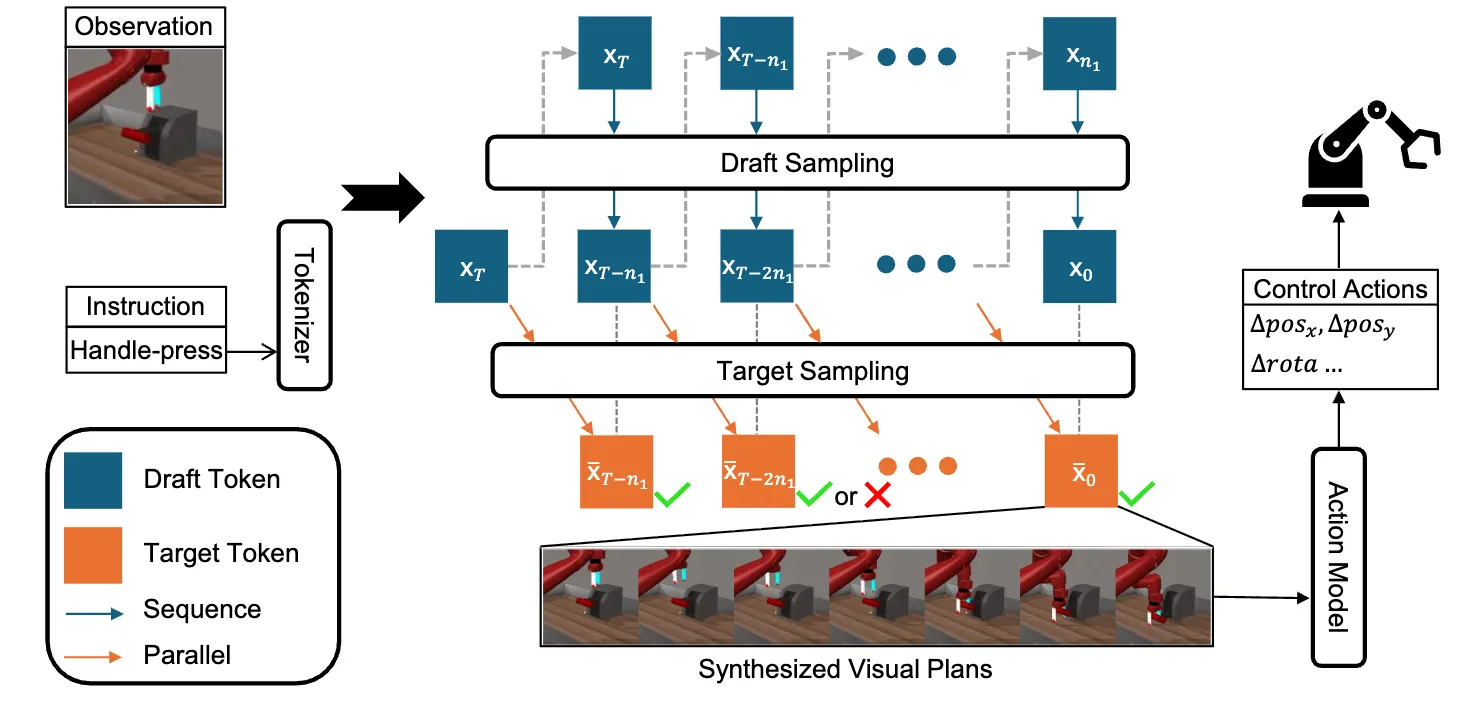
본문에서 Spec-VLA는 OpenVLA를 target으로 두고 별도 draft model을 scratch에 가깝게 학습한 반면, 자기들은 single-model / training-free 구조로 간다고 직접 비교
→ “Spec-VLA의 draft model 학습비용을 어떻게 제거할 것인가”
연구 공백 찾기
- 정적 threshold → 동적 threshold 축: KERV
- real-world 검증 축: Spec-VLA 원논문 한계였지만, HeiSD와 SpecPrune-VLA가 해결
- drafter-only → hybrid retrieval+drafters 축: HeiSD
- Action-chunk speculative decoding
action chunking을 Limitation으로 직접 남겼는데 여전히 threshold / hybrid / kinematics 중심
→ chunk-level speculative verification이나 chunk-wise acceptance rule은 블루오션
- Training-free / self-speculative token VLA
Spec-VLA는 draft model 학습이 들어감
→ token-based AR VLA 자체에서 training-free self-speculative decoding은 아직 X
Draft-and-Target Sampling은 다른 패러다임에서 그 비용 제거
- Safety-aware / uncertainty-aware acceptance
KERV가 threshold를 동적으로 바꿨지만,
formal safety constraint, calibrated uncertainty, risk-sensitive fallback까지 들어간건 없음
추가로 real robot 안전성까지?
- Pruning + SD + retrieval 통합 스택
SpecPrune-VLA는 pruning, HeiSD는 hybrid SD, KERV는 kinematic rectification 각자 따로
이 셋을 하나의 runtime policy로 묶는 “언제 pruning, 언제 retrieval draft, 언제 learned drafter, 언제 AR fallback” 할지 system paper 방향으로